目次
はじめに
こんにちは。学生エンジニアのゆうき(@engieerblog_Yu)です。
今回は、データサイエンス入門ということでscikit-learnというデータ分析のライブラリについて紹介していきたいと思います
今回の記事をお勧めする方は
データサイエンスに興味がある
scikit-learnを使ってみたい
機械学習を勉強してみたい
kaggleに挑戦してみたい
に当てはまる人です。
ちょっと気になるにゃ。
機械学習について理解が浅い方は以下の記事も合わせてどうぞ。
Scikit-learnとは?

Scikit-learnは、Pythonを使って簡単に機械学習を行うことができるライブラリです。
Scikit-learnで扱える問題は以下の4つです。
【教師あり学習】
・回帰
・分類
【教師なし学習】
・クラスタリング
・次元削減
四つだけしかないなんてちょっとガッカリにゃ。
実はこの四つの機械学習の手法が簡単にできるだけでもすごいことなんです。
なぜなら一つ一つの手法に対して機械学習のモデルはたくさんあるからです。
一つ一つのモデルを組み立てる手間を省いてくれるのが、Scikit-learnなのです。
またScikit-learnには現時点で7つのデータセットが用意されています。
| データセットの種類 | 問題 |
| ボストンの住宅価格 | 回帰 |
| 糖尿病の進行状況 | 回帰 |
| 生理学的測定結果と運動結果 | 回帰 |
| ワインの種類 | 分類 |
| アイリスの種類 | 分類 |
| 手書き文字 | 分類 |
| がんの診断結果 | 分類 |
わざわざデータを探したり、ダウンロードしなくていいので楽です。
Sciket-lernではモデルが既に構築されており実装の手間を省ける
データセットが豊富
ただしどのようなモデルがどう作られているのかは常に理解しておくことが大切です。
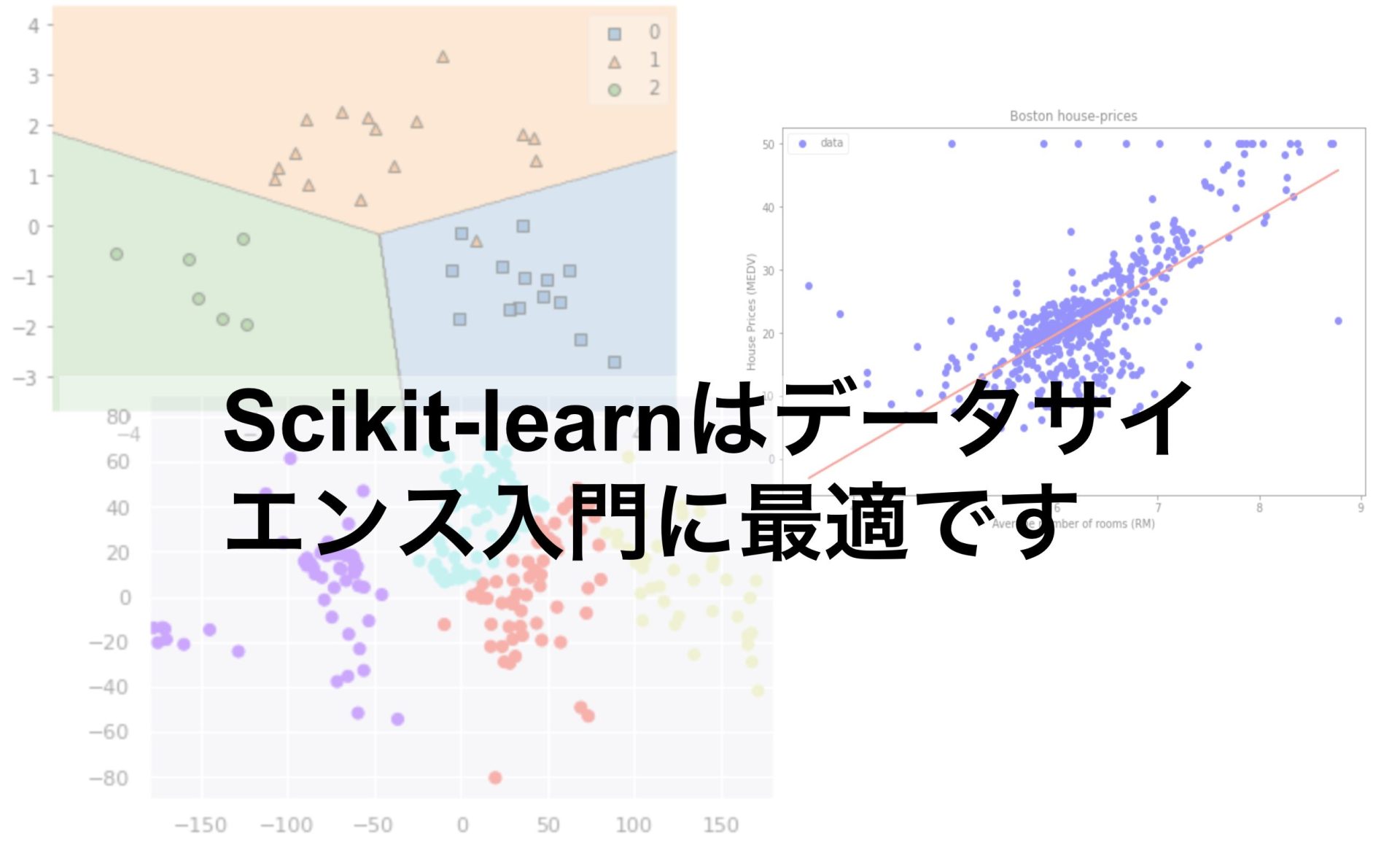
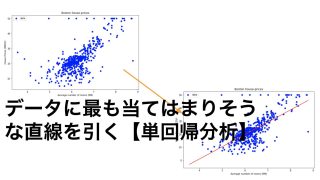
回帰(教師あり学習)

回帰とはデータに最も当てはまりの良い関数f(x)を構築することを考えます。
以下の記事ではボストン住宅価格を回帰分析を用いて予測しています。
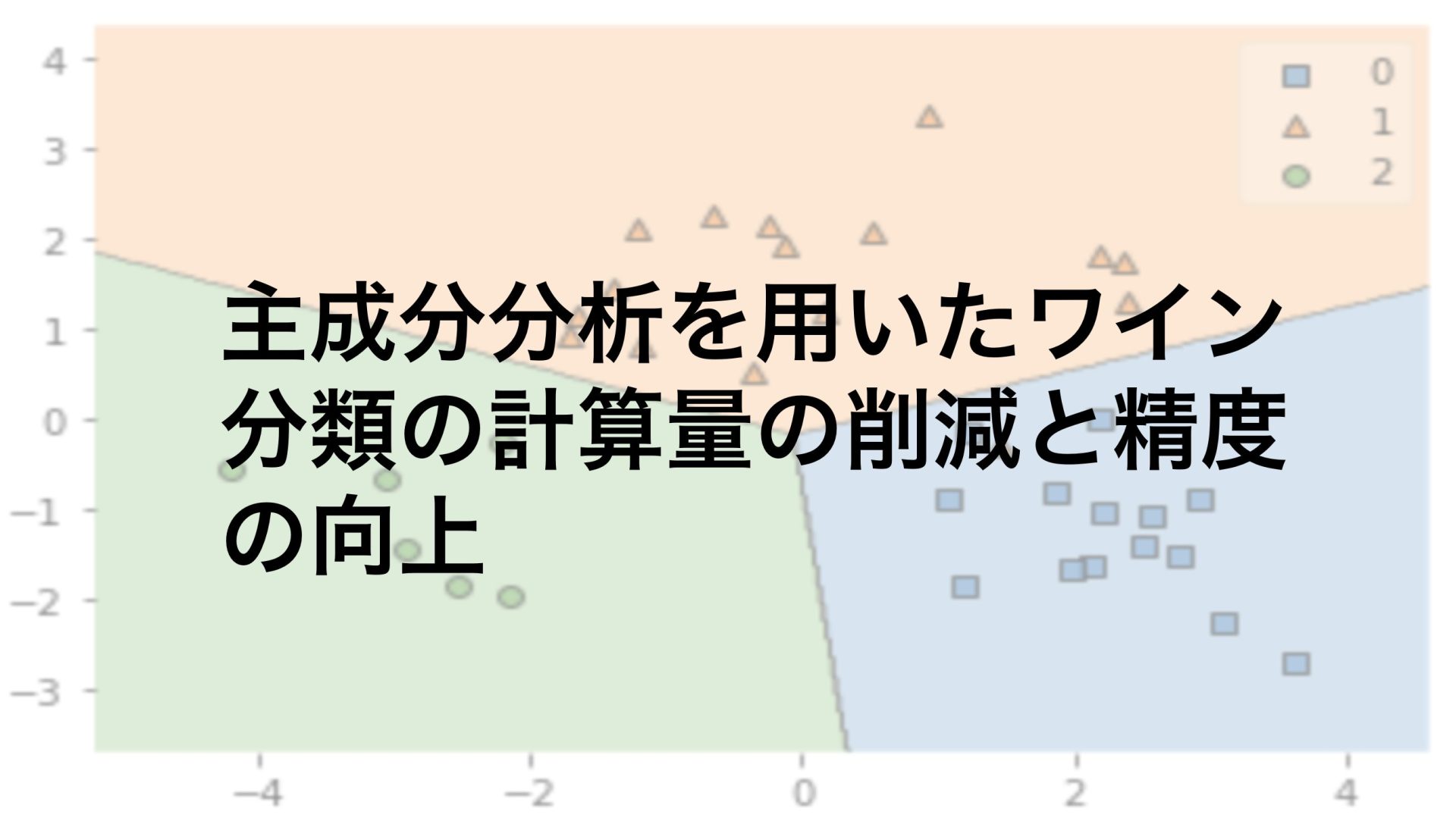
分類(教師あり学習)

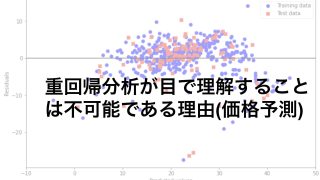
分類問題ではデータがどのクラス(集団)に所属しているのかをより適切に出力するモデルを考えます。
以下の記事ではワイン分類やタイタニック号の生存者の予測をロジスティック回帰やランダムフォレストなどの手法を使って予測しています。

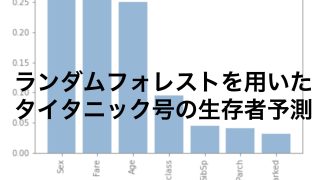
タイタニックは名作にゃ。
クラスタリング(教師なし学習)

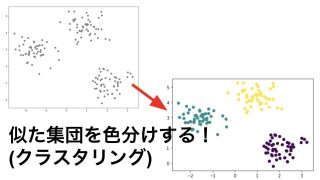
クラスタリングとは与えられたデータを自動的に分類することを考える手法です。
以下の記事ではランダムに作成したデータをKMeansを使って分類しています。
次元削減(教師なし学習)

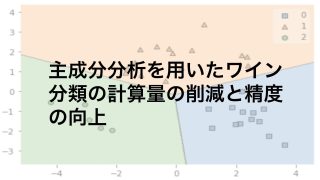
次元削減ではデータの元情報をできるだけ損なわずに計算量を減らすことを考えます。
ビッグデータを扱うことが多いデータサイエンスにはなくてはならない手法です。
Scikit-learnお勧め書籍
Scikit-learnの入門書籍はこちらがおすすめです。
本書を読んで私がいいなと思った点についてです。
モデルがどのようなアルゴリズムから構成されているのか丁寧な解説がなされている
モデルのパラメータや読者が疑問に思いそうな点についてコラムにまとめられている
コードが簡潔
入門者に特におすすめの書籍です。
一人で勉強するのが不安なあなたへ
一人で勉強するのがやっぱり不安、、、
書籍ではなく直接講師から教わりたい
という方にはAIBoostというプログラミングスクールがおすすめです。
AIBoostには以下の二つのコースがあります。
・AIエンジニアコース:python基礎から学習し機械学習を用いたWebアプリの開発をおこないます。
・データサイエンスコース:python基礎から統計学や分析までを学習し、データサイエンティストになるための素養を身につけます。
本気でデータサイエンティストになってバリバリ稼ぎたいという方はAIBoostのデータサイエンスコースがおすすめです。
以下のリンクから無料カウンセリングを申し込むことができます。
おわりに

今回はデータサイエンス入門としてScikit-learnについて紹介しました。
機械学習に取り組んでみたい方は、まずはScikit-learnから初めてみるのがお勧めです。
一緒に頑張っていきましょう!
他にもいろんな投稿があるにゃ。



コメント