目次
はじめに
こんにちは。学生エンジニアのゆうき(@engieerblog_Yu)です。
今回はscikit-learnというデータ分析のライブラリを使ってワイン分類を行っていこうと思います。
今回の記事をお勧めする方は
データ分析に興味がある
scikit-learnを使ってみたい
機械学習を使って分類問題を解いてみたい
に当てはまる人です。
今回の制作物
今回はこのようなワインのデータセットを使って以下の画像のように分類を行っていきます。
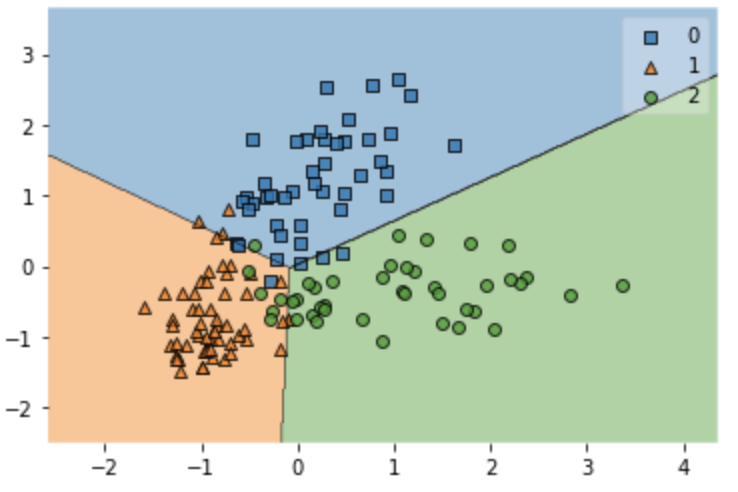
今回は注目するのはClass labelという列です。
Class labelに値する、ワインの種類を他のデータから予測できるように機械学習を行っていきます。
お酒は飲めないにゃ。
まずは教師あり学習についての説明です。
教師あり学習について
教師あり学習とは正解データが事前に用意されているものです。
反対に教師なし学習であれば正解データは事前に用意されていません。
分類問題は教師あり学習に分類され、教師あり学習には主に以下の二つのものがあります。
【教師あり学習】
・回帰問題
・分類問題
今回行うものは教師あり学習の分類問題ということをしっかり理解していただきたいと思います。
わかったにゃ。
また回帰問題についての記事も投稿しています。
ロジスティック回帰について

次にロジスティック回帰とは何なんかということについてです。
ロジスティック回帰は主に○か×かで表されるデータに対して使われます。
例えば
試験に合格するか否か
タイタニック号に乗っていた人が生きているか死んでいるか
などです。
○×で表されるデータは数値で表すデータが量的データと表されるのに対して質的データといいます。
ロジスティック回帰は予測モデルの出力が必ず0から1の値をとります。
上記の試験で例えると
0が不合格、1が合格と対応させて、出力結果が0.8であれば合格する確率は80%ということです。
ロジスティック回帰の式はこのようになります。
$$y=\frac{1}{1+e^{-\theta ^{T}x}}$$
$$\theta=\left( \theta _{1}\theta _{2}\ldots \cdot \theta _{n}\right) ^{T}$$
難しそうだにゃ。
この場合のθは説明変数の値を表しています。
試験であれば勉強時間であったり、部活に入っているか否か、などの値が入ります。
図で表すとこのようになります。
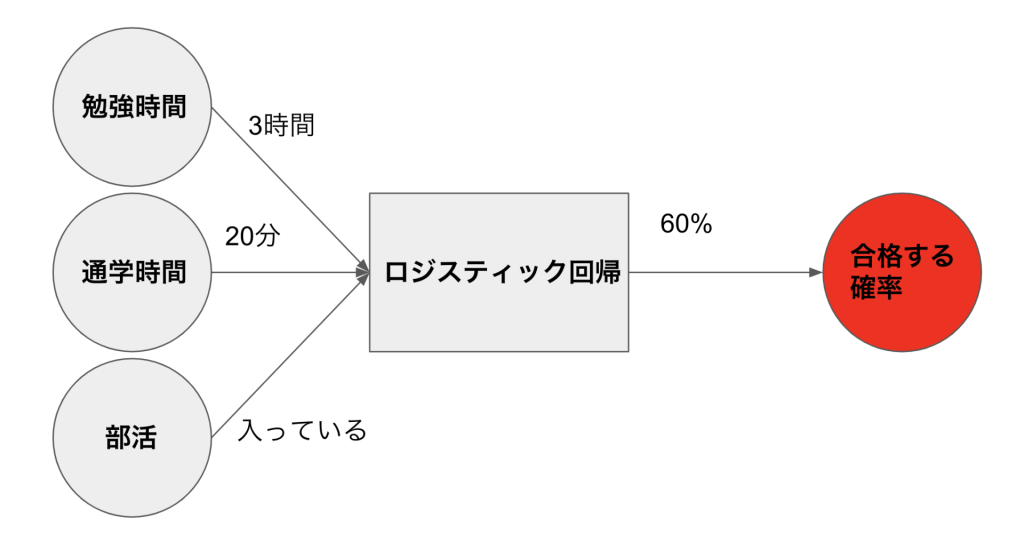
ロジスティック回帰は勉強時間、通学時間、部活などの情報を入れると合格する確率を出力してくれるというようなものです。
なんとなくわかったにゃ。
ロジスティック回帰の予測モデルをグラフで表すと以下のようなものになります。
以下のシグモイド関数と呼ばれるものを基本としθの値によって形状が変わります。
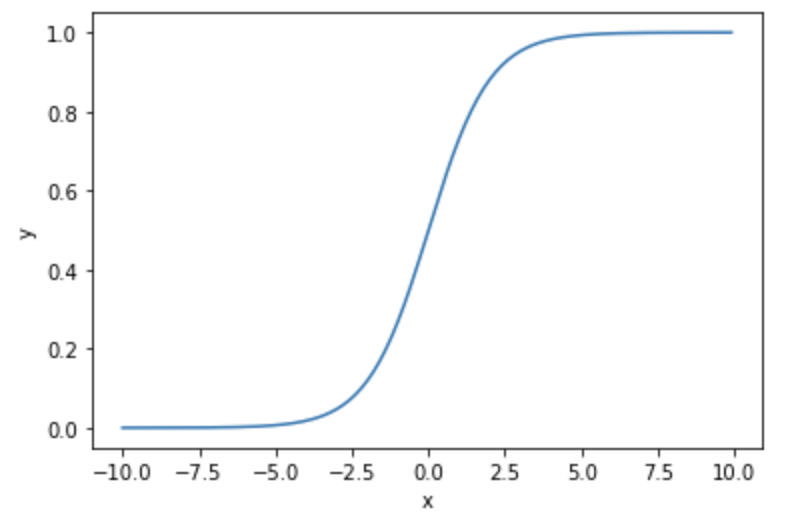
といっても式を見ていただけたら分かるとおり、θが変化しても、yの値が0から1であることは変わりません。
やっぱり、難しいにゃ。
難しいと思った方はとりあえずロジスティック回帰は○×問題を解けるくらいの認識で大丈夫です。
ところで不思議に思っている方はいませんか?
ロジスティック回帰には○か×かの2クラスに分けるだけの機能しかないのに今回は3クラスに分けることができています。
ロジスティック回帰で3クラス以上に分類したいときはOVR(One Vs Rest)といった手法を使うことができます。
OVR(One Vs Rest)について
ロジスティック回帰で多クラス分類を行いたい時に使われる手法の一つにOVRがあります。
OVRの原理は簡単で、多クラスをロジスティック回帰を用いて二つに分けるという作業を繰り返すことで分類するといったものです。
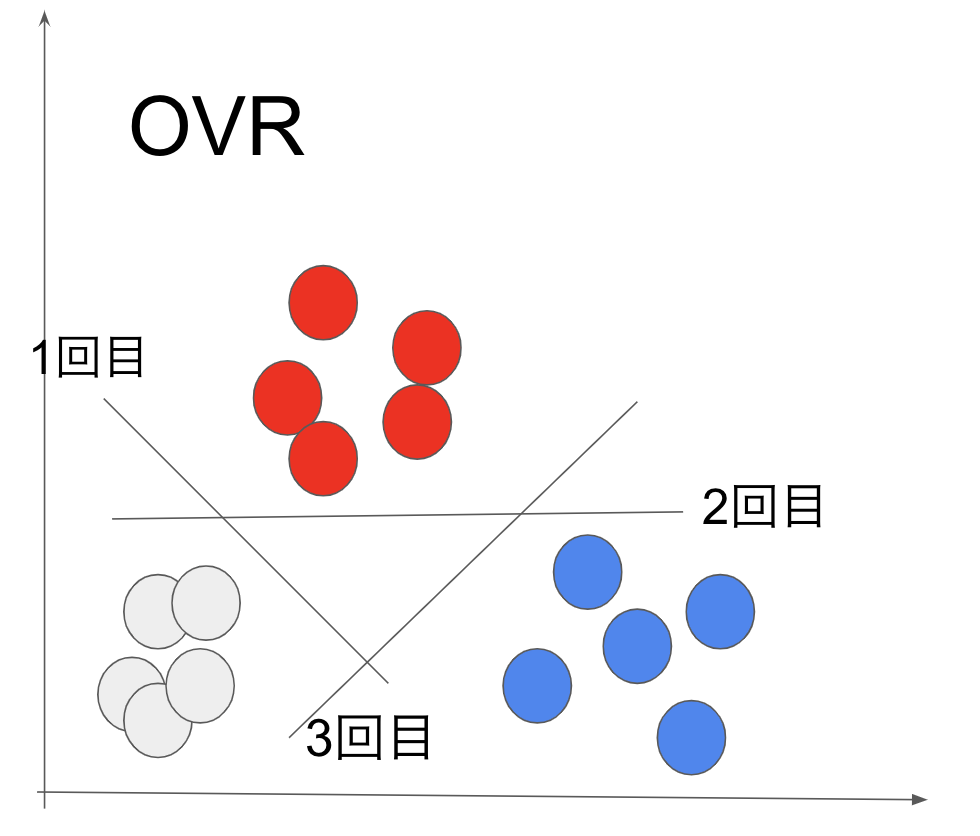
つまり今回のような3クラス分類であれば2クラスに分ける作業を3回行うということです。
これによって3クラスそれぞれの境界を求めることができます。
それでは実際に分類問題を解いていきましょう!
ライブラリのインポート
今回使用するライブラリは以下です。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from mlxtend.plotting import plot_decision_regions
from sklearn.ensemble import RandomForestRegressorデータの読み込み
まずはワインのデータを読み込んでいきましょう。
#データの読み込み
df_wine = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data',header=None)
# カラムの名前の設定
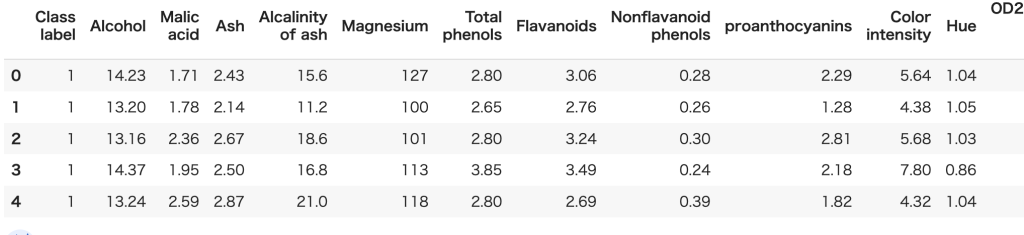
df_wine.columns = ['Class label','Alcohol','Malic acid','Ash','Alcalinity of ash','Magnesium','Total phenols','Flavanoids','Nonflavanoid phenols','proanthocyanins','Color intensity','Hue','OD280/OD315 of diluted wines','Proline']# データの確認
df_wine.head()しっかり読みこめてるにゃ。
説明変数と目的変数の代入
今回は10番目の色の要素と13番目のプロリンの量を説明変数としました。
なぜこの二つを説明変数にしたかについては後ほど述べます。
# 説明変数と目的変数の代入
X = df_wine.iloc[:,[10,13]].values
y = df_wine.iloc[:,0].values-1訓練データとテストデータの分割
今回は訓練データとテストデータを8:2に分割していきます。
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=0)慣例としては割合は8:2か7:3が良いとされています。
標準化
次にデータを揃えるために標準化を行っていきます。
標準化を行うことでデータの平均が0、標準偏差が1になります。
# 標準化を行う
sc = StandardScaler()
X_train_std = sc.fit_transform(X_train)
X_test_std = sc.fit_transform(X_test)ロジスティックモデルの作成
ロジスティックモデルのパラメータについての説明です。
| max_iter | 勾配降下法を行う回数 |
| multi_class | 多クラス分類の方法を’ovr’,’multinomial’,’auto’から選ぶ |
| solver | 計算に使用するライブラリ |
| C | 正則化の強さを表し、値が大きいほど正則化の効果は弱くなる |
| penalty | 正則化を’l1′,’l2′,’elasticnet’から選択 |
| l1_ratio | elasticnetを選んだ時のl1正則化の割合を指定する |
| random_state | 乱数のシードを指定 |
今回は先ほど説明したovrを使っていきます。
# ロジスティックモデルの作成
logistic_model = LogisticRegression(max_iter=100,multi_class='ovr',solver='liblinear',C=1.0,penalty='l2',l1_ratio=None,random_state=0)model.fit(X_train_std,y_train)それでは出来上がったモデルがどんなもんか確かめていきましょ〜。
モデルの評価
# モデルの評価
y_test_pred = model.predict(X_test_std)
ac_score = accuracy_score(y_test,y_test_pred)89パーセント程度の正確さで予測できていることがわかります。

訓練データの結果のプロット
それでは訓練データとテストデータをそれぞれプロットしていきましょう。
plt.figure()
plot_decision_regions(X_train_std,y_train,model)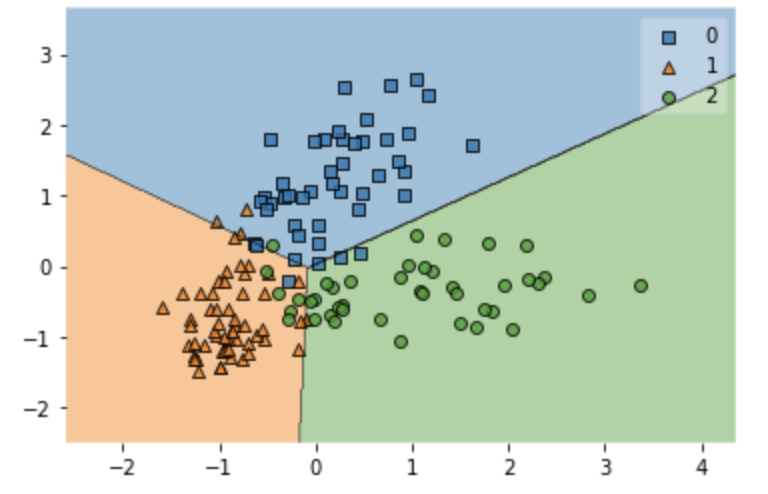
テストデータの結果のプロット
次に本当にモデルが良いものなのかどうかテストデータで確かめてみましょう。
plt.figure()
plot_decision_regions(X_test_std,y_test,model)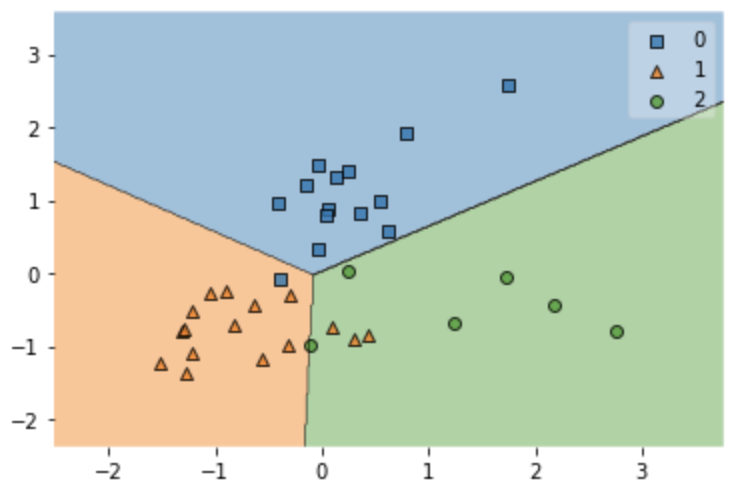
89%で予測できているので大方良いモデルだと思います。
ランダムフォレストを用いた特徴量の重要度の確認
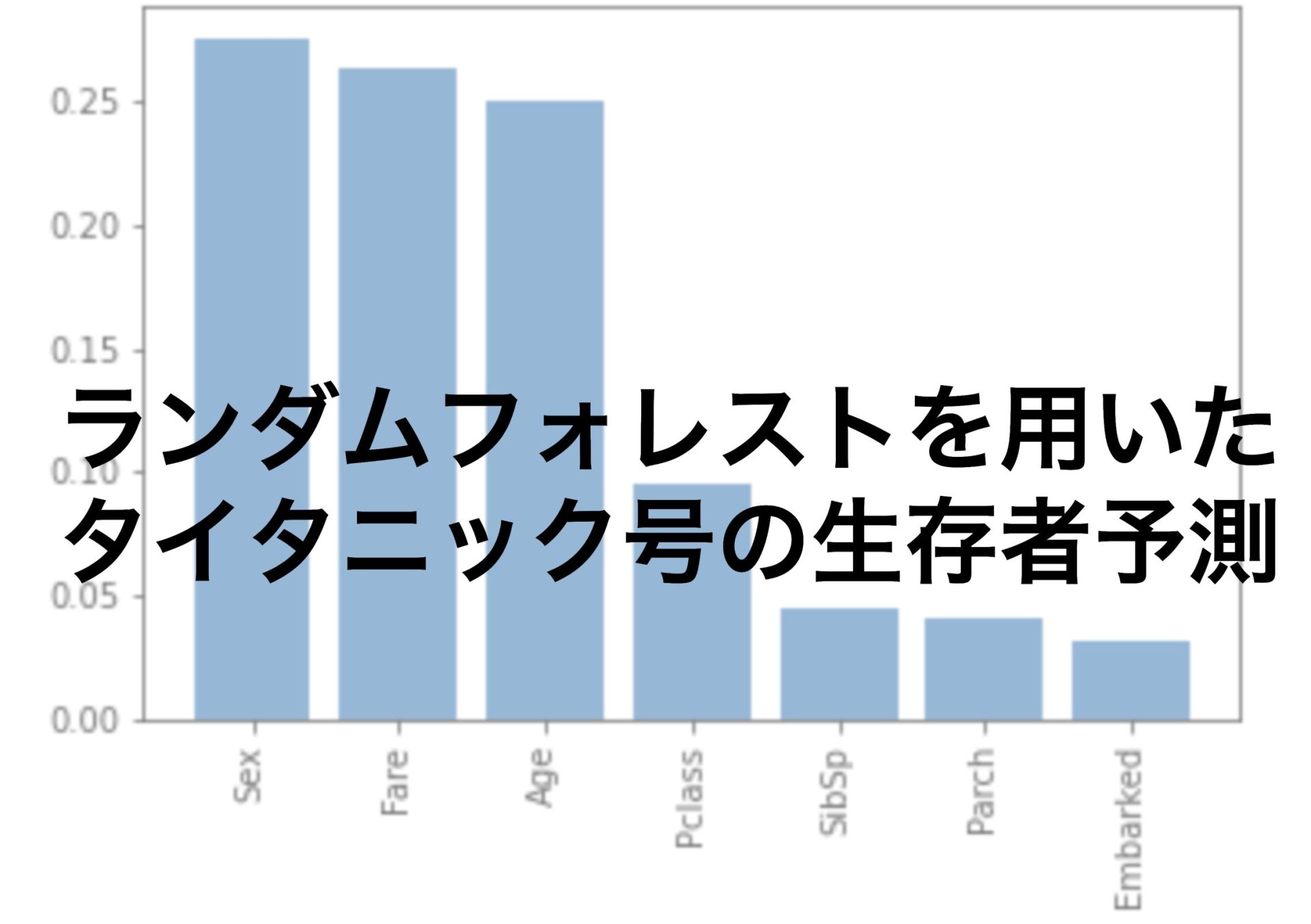
最後に何故10番目と13番目の項を選んだのかについて説明したいと思います。
ランダムフォレストというモデルを使うと特徴量の重要度を評価することができます。
# 説明変数と目的変数の代入
X = df_wine.loc[:,"Alcohol":"Proline"].values
y = df_wine.iloc[:,0].values-1
#訓練データとテストデータの分割
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=0)
# モデルの作成
forest_model = RandomForestRegressor(bootstrap=True,n_estimators=1000,criterion='mse',max_depth=None,random_state=0,n_jobs=-1)
# モデルにフィットさせる
forest_model.fit(X_train,y_train)以下の配列を見ると10番目と13番目の値が大きいことがわかります。

ランダムフォレストで分類問題を解いている記事も合わせてどうぞ。

おわりに

今回はscikit-learnというデータ分析のライブラリを使ってワイン分類を行っていきました。
データサイエンスを少しでも楽しんでいただけたら嬉しいです。
続きとして主成分分析を使った記事もお勧めです。
おまけ(Pythonを使ったAIアプリ開発や画像認識に興味がある方)
どうせ勉強するなら何か、目標を持って学習したい
Python基礎を身につけるだけでなく、稼げる力をつけたい
これらに当てはまる方は、株式会社アイデミーが立ち上げている、オンラインプログラミングスクールAidemy Premiumがおすすめです。
Aidemy Premiumの特徴としては
3ヶ月の短期集中型の講座で、Pythonを使ったAIプログラミングを学ぶことができる
専属のメンターが学び方や進捗などを管理してくれる
完全オンライン
AIエンジニアやデータサイエンティストに興味のある方は、特におすすめのスクールです。
プログラミング初心者の方でも、AIを使った画像認識やアプリ開発なども学ぶことができます。
今なら無料オンライン相談が実施されているので、話だけでも聞いてみるのをおすすめします。
対象のサイトはこちら他にもいろんな投稿があるにゃ。

コメント