
目次
この記事をおすすめしたい人

どーも、学生エンジニアのゆうき(@engineerblog_Yu)です。
・めんどくさいことが嫌いな人
・プログラミングで手っ取り早くデータ収集がしたい人
・Pythonで案件を受注したい人
・Pythonの自動化を勉強したい人
今回の記事はこれらの一つでも当てはまった人むけの記事です。
それではまずはWebスクレイピングとは何か簡単に解説していこうと思います。
noteで完全版を公開中です。
Webスクレイピングとは?
ウェブスクレイピング(英: Web scraping)とは、ウェブサイトから情報を抽出するコンピュータソフトウェア技術のこと。
Whikipediaより
Webスクレイピングのメリット

・手作業を使わずに自動的に大量のWebサイトの情報を集めることができる
手作業でコピーアンドペーストすることなしにWeb上から情報を自動的に集めることができます。
・APIを提供していないWebサイトからも情報を収集することができる
APIは必ずしも全てのWebサイトに適用されているわけではないのでAPIが使えないWebサイトからも情報を収集することができます。
Webスクレイピングのデメリット

・収集先のWebサイトからスクレイピングが拒否されたり法律違反となってしまう場合がある
Web上の情報は公開情報のため安易にスクレイピングをしてしまいがちですが利用規約などにスクレイピングが禁止されていたり、スクレイピングができなくなっている場合もあります。
スクレイピングをする場合は利用規約をしっかり確認してから行うようにしましょう。
また同じページに複数回アクセスしてサーバーに負担をかけることは禁止されているので以下に説明しているサーバーに負担をかけない方法を取りましょう。
Pythonについて

Pythonとは人工知能、機械学習、ディープラーニング、データ解析などに特化しており、2020年プログラミング言語人気ランキング1位になっているプログラミング言語です。
Pythonについて詳しく知りたい方はこちらのウェブサイトをどうぞ。
それでは本格的にWebスクレイピングのやり方を説明していきたいと思います。
BeautifulSoupを使ったWebスクレイピング

今回はPycharmという開発環境を用いてWebスクレイピングを行っていこうと思います。
anaconda3をインストールしていない方は最初にターミナル上で
pip install bs4と入力してあげてください。
それではコードを書いていきましょう。
今回はPythonのWebサイト(https://www.python.org)をスクレイピングしていきましょう。
まずはBeautifulSoupとrequestsをimportしてあげましょう。
from bs4 import BeautifulSoup
import requestsそれでは最初にWebサイトのhtmlを表示してみます。
html = requests.get('https://www.python.org')
print(html.text)こちらのコードを打ち込んであげればPythonのWebサイトを構成しているhtmlがターミナル上に表示されると思います。
それでは次に欲しい情報だけを抽出していきましょう。
今回はPythonの公式Webサイトのtitleタグの部分の情報だけを抽出していこうと思います。
こちらのコードを実行してみてください。
from bs4 import BeautifulSoup
import requests
html = requests.get('https://www.python.org')
soup = BeautifulSoup(html.text, 'lxml')
titles = soup.find_all('title')
print(titles)すると
[<title>Welcome to Python.org</title>]と表示されると思います。
これはPythonの公式Webサイト上で使われているtitleタグはこの一つだけということを指しています。
たまたま一つだっただけですがたくさんある場合は全てのtitleタグがリスト型で表示されます。
リストがわからない方はこちらの記事も合わせてどうぞ。

またprintでtitles[0].textを表示してあげれば
Welcome to Python.orgと表示されます。
同じようにクラスの中の情報を抽出したい場合には
(変数名) = soup.find_all('タグ名', {'class': 'クラス名'})としてあげれば良いです。
タグ名とはdivとかpとかh1などのHTMLタグのことです。
htmlについてあまりよくわからない方は「html タグ一覧」などググってみるのが良いと思います。
サーバーに負担をかけない方法
サーバーに負担をかけないためにはsleep関数を用います。
まずはこのようにimportしてあげます。
from time import sleep何度もサイトにアクセスする場合には最低でも3秒は操作をストップした方が良いと言われているのでfor文などを用いるときは適宜sleepメソッドを使いましょう。
sleep(3)それでは最後にまとめです。
まとめ
from bs4 import BeautifulSoup
import requests
html = requests.get('https://www.python.org')
soup = BeautifulSoup(html.text, 'lxml')
(変数名) = soup.find_all('タグ名', {'class': 'クラス名'})最後の行のsoup.find_allのカッコの中に自分が欲しい情報を選択してあげればWebスクレイピングを行うことができます。

Pythonの勉強方法【おまけ】
Pythonの基礎文法を勉強するにはUdemyというオンラインプログラミング学習プラットフォームがおすすめです。
具体的に言うとこちらの講座です。
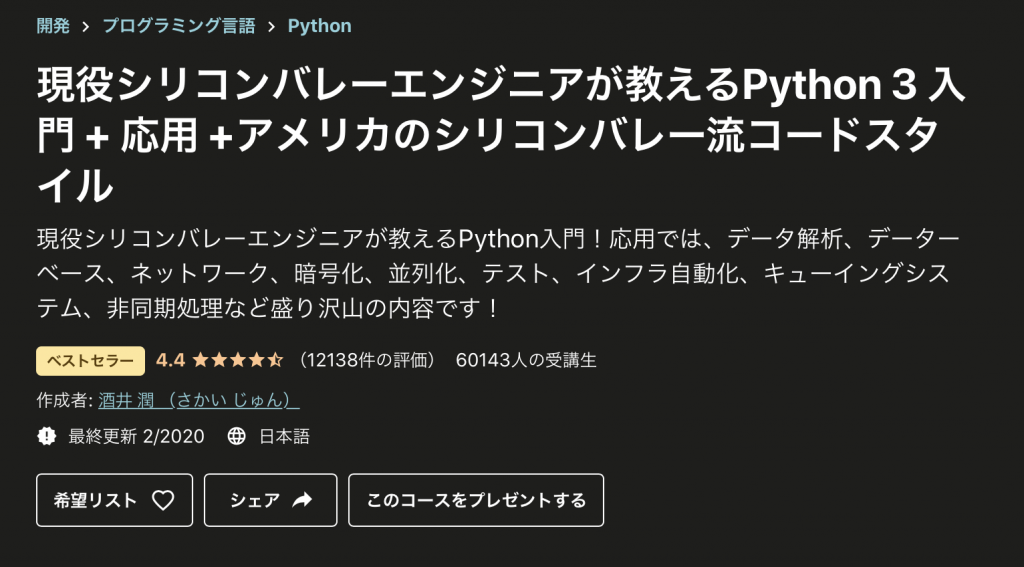
この講座だけで基礎文法だけでなく実践的な応用スキルまで身につけることができます。
めちゃくちゃわかりやすい講座なので気になる方は是非みてみてください。
私が受けたPythonの講座の中では最も良かったですし、この講座だけで案件を獲得できるようになるレベルまでプログラミングを上達させることができると思います。
実際多くの人がWeb上で高評価をしていてUdemyのPython講座といえばこの講座と言われているほどです。
今回紹介したBeautifulSoupを用いたWebスクレイピングもこの講座の中でより詳しく述べられています。
以下のリンクからUdemy講座を参照することができます。
自分の未来に投資しよう。サイバーセール中はUdemyコースが最大90%OFF。おわりに

今回はWeb上からのデータ収集がめんどくさい方むけにWebスクレイピングについて紹介しました。
自動化はPythonの強みなのでPythonを勉強したい方は学んでおくべき内容だと思います。
興味がある方はUdemyのコースを受けてみるのも良いかと思います。





コメント