目次
はじめに

どーも、学生エンジニアのゆうき(@engineerblog_Yu)です。
今回はデータサイエンスの入り口として移動平均線を書いていこうと思います。
・データサイエンスに興味がある方
・グラフの可視化に興味がある方
・機械学習などに取り組んでみたい方
には特におすすめの記事となっています。
今回の作成物
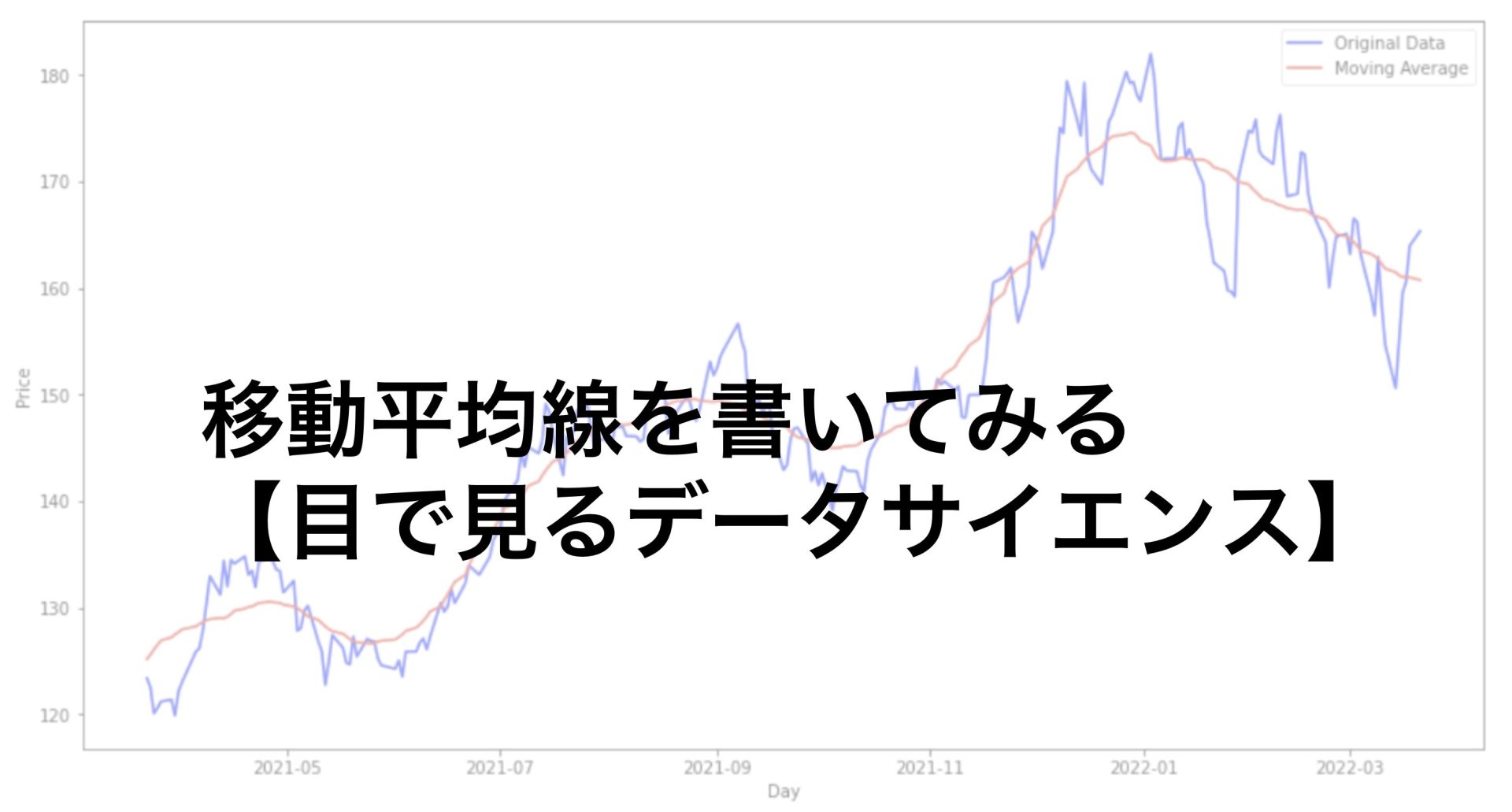
今回は実際のApple社の株価データを用いて移動平均線を表示してみましょう。
移動平均線とは付近の何日間かのデータの平均をとった値をプロットして線でつなげるといったものです。
株価データの指標としては良く使われるものですね。
それではまずは全体のコードをお見せしようと思います。
全体のコード
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_csv('株価データ.csv')
# データの前処理
df = df.iloc[::-1]
df.index = range(len(df))
# 日付の整形
df['日付け'] = pd.to_datetime(df['日付け'], format='%Y年%m月%d日')
data = df.loc[:,'終値']
x = df.loc[:,'日付け']
# データの要素数
num_data = np.size(data)
# 移動平均の計算結果の格納するための配列を作成
moving_average = np.zeros(num_data)
# 前後いくつのサンプルを用いて平均値を求めるか
k = 15
#移動平均線の計算
for n in range(num_data):
if n - k < 0:
# 0日目より前のデータは平均計算に使用しない
moving_average[n] = np.mean(data[:n+k+1])
elif n + k >= num_data:
# データの最終日より後ろのデータは平均計算に使用しない
moving_average[n] = np.mean(data[n-k:])
else:
moving_average[n] = np.mean(data[n-k : n+k+1])
#グラフの表示
plt.figure(figsize=(15,8))
plt.plot(x, data, label='Original Data', color='b')
plt.plot(x, moving_average, label='Moving Average', color='r')
plt.xlabel('Day')
plt.ylabel('Price')
plt.legend()
plt.show()それではコードの解説の方に移っていきます。
生データの確認
まずは時系列データを表示していきましょう。
今回用いるデータはアップル社のサイトから取ってきたCSVデータです。
みなさんもぜひ実際にダウンロードしてみてください。
名前は株価データ.csvとして作業ファイルと同じディレクトリに配置しました。
このようなものです。
このデータの問題点として
・日付が逆順になっている
・情報がたくさん入っている
といったことが挙げられます。
今回は簡単のために終値だけに着目していこうと思います。
データの前処理(ライブラリのインポートとCSVデータの読み込み)
import pandas as pd
import numpy as np
import matplotlib.pyplot as pltまずは必要なライブラリをインポートしていきましょう。
基本的にデータサイエンスで用いるのは上記の三つのライブラリです。
それぞれのライブラリについて解説している記事もあるので自信がない方は合わせてどうぞ。



まずはcsvデータを読み込んでいきましょう。
df = pd.read_csv('株価データ.csv')こちらのコードでdfという変数の中にcsvの情報を格納することができます。
dfというのはdataframeの略です。
次に本格的にデータの前処理を行っていきましょう。
データの前処理(並べ替えと日付の型変換)

まずデータを古い順からに並び替えてあげましょう。
#データを逆順に並び替える
df = df.iloc[::-1]
df.index = range(len(df))ilocメソッドを上記のように使ってあげるとdfのインデックス番号以外が逆順になってくれます。(これはこういうものなんだなという認識で大丈夫です。)
そしてインデックス番号のみを順番通りに並び替えるために2行目のコードを実行します。
df.indexというのはdfのインデックス番号に値するものです。
rangeというのは自然数を0から返してくれるもので例えばrange(2)とするとリスト形式で(0,1)が返されます。
len(df)はdfの長さを返してくれるものです。
次に時系列データの日付カラムの値をDatetime型に変換していきます。
日付カラムはDatetime型に変換する方が何かと使い勝手が良いので変換することをお勧めします。
具体的にはこの欄ですね。

この欄を以下のコードでdatetime型に変換していきます。
# 日付の整形
df['日付け'] = pd.to_datetime(df['日付け'], format='%Y年%m月%d日')今現在日付は2022年03月21日という形なのでformatという引数で2022がY(年)、03がM(月)21がD(日)にあたるということを指定してあげます。
するとdatetime型はY-m-dという形で表されるので2022-03-21という形になります。
現時点での時系列データの表示
それでは今の時点での時系列データを表示していこうと思います。
まず最初に全体のコードを載せます。
# dfの終値の列の値だけを取り出す
data = df.loc[:,'終値']
# dfの日付の列の値だけを取り出す
x = df.loc[:,'日付け']
#グラフを表示する
plt.figure(figsize=(15,8))
plt.plot(x, data, label='Original Data', color='b')
#X軸のラベル
plt.xlabel('Day')
#Y軸のラベル
plt.ylabel('Price')
plt.legend()
plt.show()上記のコードを実行して表示されたグラフが以下のグラフです。
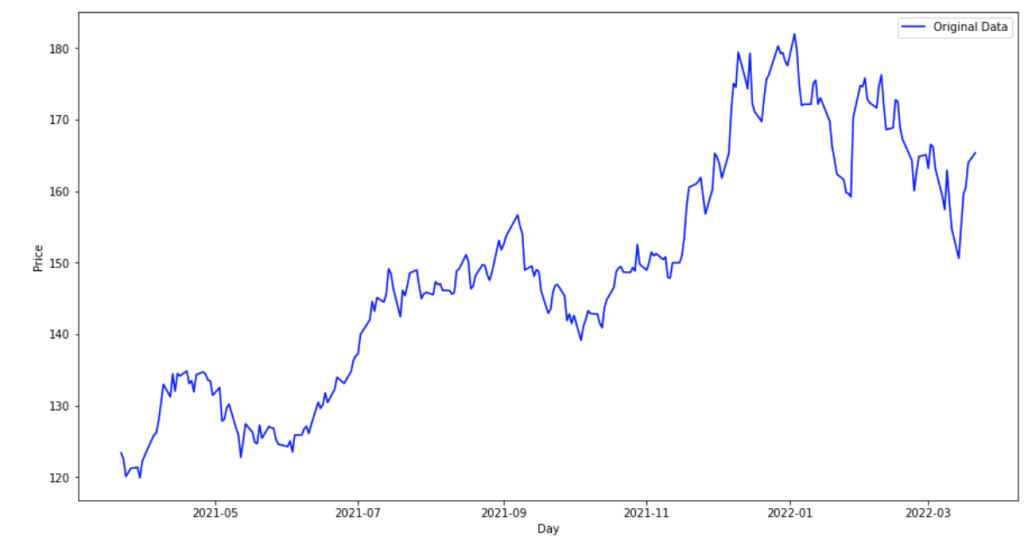
一つ一つ解説していきますね。
以下はdfの任意の列の値だけを取り出すメソッドです。
# dfの終値の列の値だけを取り出す
data = df.loc[:,'終値']
# dfの日付の列の値だけを取り出す
x = df.loc[:,'日付け']pandasのlocメソッドは一つ目の引数に行の範囲をとり、二つ目の引数に列の範囲をとります。
例えばdf.loc[0:1,2:3]とするとdfの0行目から1行目でかつ2列目から3列目のデータフレームを抜き出すことになります。
「:」の前後に数字を入れないと全ての行or列という指定になります。
次はグラフの表示に関してです。
#グラフを表示する
#グラフのサイズ設定
plt.figure(figsize=(15,8))
#グラフのプロット
plt.plot(x, data, label='Original Data', color='b')
#X軸のラベル
plt.xlabel('Day')
#Y軸のラベル
plt.ylabel('Price')
#グラフの凡例表示
plt.legend()
#グラフの表示
plt.show()グラフのプロットに関しては
第一引数にx座標の値、第二引数にy座標の値、第三引数にグラフの凡例、第四引数に色を取っています。
凡例というのはグラフの以下の部分です。

アルフォート美味しいよね。
移動平均線の表示(メイン)

それではメインとなる移動平均線に移っていきます。
今回も最初に全体のコードを載せます。
# データの要素数
num_data = np.size(data)
# 移動平均の計算結果の格納するための空の配列を作成
moving_average = np.zeros(num_data)
# 前後いくつのサンプルを用いて平均値を求めるか(ここの値はそれぞれ変更する)
k = 15
#移動平均線の表示
for n in range(num_data):
if n - k < 0:
# 0日目より前のデータは平均計算に使用しない
moving_average[n] = np.mean(data[:n+k+1])
elif n + k >= num_data:
# データの最終日より後ろのデータは平均計算に使用しない
moving_average[n] = np.mean(data[n-k:])
else:
moving_average[n] = np.mean(data[n-k : n+k+1])まず移動平均線の考え方についてです。
移動平均線とは前後いくつかの平均を取って時系列データを滑らかにするという手法です。
今回は前後15サンプルについて考えます。
つまり30個のデータの平均値について考えます。
例えば30番目のデータについて考えると15番目~46番目のデータを平均した値が平均値として採用されます。
最初の15番目までや最後から15番目までは前後のデータが不足しているため平均計算には利用しません。
それをif文の中で考えています。
#移動平均線の計算
for n in range(num_data):
if n - k < 0:
# 0日目より前のデータは平均計算に使用しない
moving_average[n] = np.mean(data[:n+k+1])
elif n + k >= num_data:
# データの最終日より後ろのデータは平均計算に使用しない
moving_average[n] = np.mean(data[n-k:])
else:
moving_average[n] = np.mean(data[n-k : n+k+1])np.meanというのはnumpyのメソッドで引数にリストを渡すとリストの値の平均値を返してくれます。
文字が多くてわかりづらいと思うのでnが30の場合として考えていきます。
data[15:46]となるので前後30個の値がリストとして切り取られます。
そしてmeanメソッドで平均値が計算されるということです。
これが0から各nの値で実行されていくということです。
グラフの表示
それでは最後にグラフの表示をしていきましょう。
こちらは先ほどのグラフの表示とほとんど同じですので割愛させていただきます。
#グラフの表示
plt.figure(figsize=(15,8))
plt.plot(x, data, label='Original Data', color='b')
plt.plot(x, moving_average, label='Moving Average', color='r')
plt.xlabel('Day')
plt.ylabel('Price')
plt.legend()
plt.show()全体のコード【再掲】
それでは最後に全体のコードをもう一度載せます。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_csv('株価データ.csv')
# データの前処理
df = df.iloc[::-1]
df.index = range(len(df))
# 日付の整形
df['日付け'] = pd.to_datetime(df['日付け'], format='%Y年%m月%d日')
data = df.loc[:,'終値']
x = df.loc[:,'日付け']
# データの要素数
num_data = np.size(data)
# 移動平均の計算結果の格納するための配列を作成
moving_average = np.zeros(num_data)
# 前後いくつのサンプルを用いて平均値を求めるか
k = 15
#移動平均線の計算
for n in range(num_data):
if n - k < 0:
# 0日目より前のデータは平均計算に使用しない
moving_average[n] = np.mean(data[:n+k+1])
elif n + k >= num_data:
# データの最終日より後ろのデータは平均計算に使用しない
moving_average[n] = np.mean(data[n-k:])
else:
moving_average[n] = np.mean(data[n-k : n+k+1])
#グラフの表示
plt.figure(figsize=(15,8))
plt.plot(x, data, label='Original Data', color='b')
plt.plot(x, moving_average, label='Moving Average', color='r')
plt.xlabel('Day')
plt.ylabel('Price')
plt.legend()
plt.show()これを実行してみると移動平均線が表示されていることがわかります。
どうだったでしょうか?
コーディングをしてみて実際にグラフが表示されると何をやっているのかわかりやすくて楽しんでいただけたら嬉しいです。
最後に
- 機械学習をやってみたい
- データサイエンスに興味がある
- プログラミングのスキルを身につけたい
という方向けにおすすめの講座を紹介したいと思います。
【おわりに】データサイエンスお勧め勉強法
結論から言うとUdemyというオンライン学習サービスのこちらの講座がおすすめです。
こちらの動画ではデータサイエンティストになるためのロードマップからそれぞれの分野について映像を用いた分かりやすい説明がなされています。
データサイエンスには以下の三つのスキルが必要と言われています。
- ビジネススキル
- 数学スキル
- プログラミングスキル
この講座を受けると
・大学数学をあまり理解できていない
・プログラミングにあまり触れたことがない
・ビジネス経験がない
という方でも総合的な理解を深めて未経験からデータサイエンティストになることも可能だと思います。
スキルを身につけて安定を得たい、プログラミングの副業をやってみたいという方に特におすすめの講座です。
一緒に頑張っていきましょう。



コメント