はじめに

こんにちは。学生エンジニアのゆうき(@engieerblog_Yu)です。
このように思っている方はいませんか?
データサイエンスに興味がある
クラスタリングについて知りたい
機械学習を使ってみたい
今回の記事を読めば
データサイエンスの基礎を学べる
クラスタリングとは何か理解できる
機械学習をクラスタリングで使えるようになる
こと間違いなしです。
それではまずはクラスタリングについての説明です。
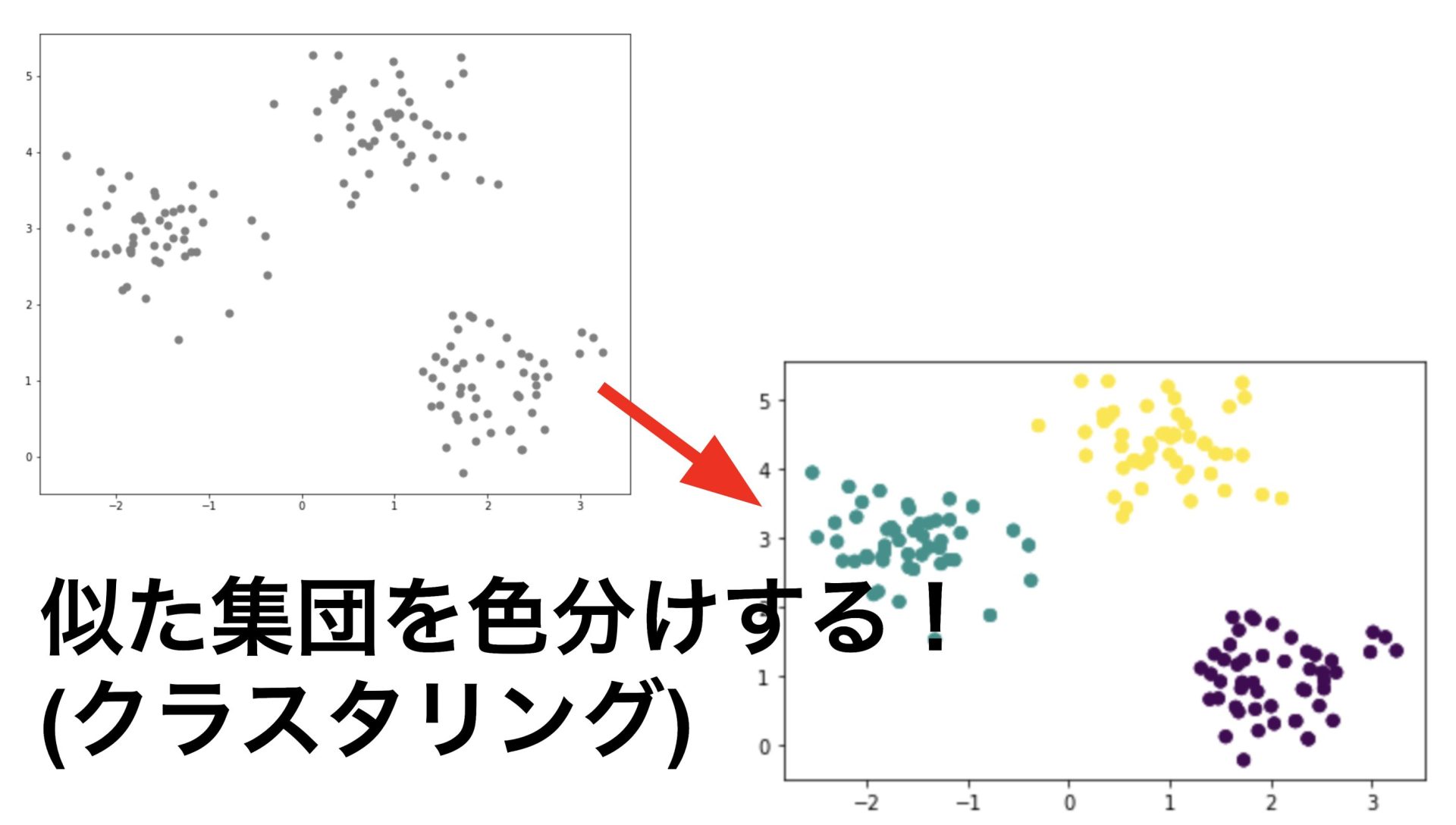
クラスタリングとは?【今回の制作物】
クラスタリングとは簡単にいうと、似ている集団を色分けするということです。
例えば動物の身体データを用いてカテゴリ分けすることもクラスタリングです。
またクラスタリングを用いて大気汚染源を特定するといったことも実際に研究されています。
なおクラスタリングは正解データ(教師データ)がないので教師なし学習と言います。
すごく簡単そうだにゃ。
しかしクラスタリングは簡単というわけでもないのです。
上記の画像を見ると人間でもすぐできそうな作業ですが、データが複雑になっていくと、そううまくもいかないわけです。
これは赤色?それとも緑色?どっちに分ければいいか微妙、、、。
などの問題が発生します。
だからプログラミングを使うのです。
プログラミングを使ってクラスタリングすることで
・どのくらい点が離れているのか数値化できる(定量化)
・データにあったアルゴリズムを選択することができる
- それぞれの点がどれくらい離れているのか数値で表すことができる(定量化)
- データにあったアルゴリズムを選択することができる
アルゴリズムとはプログラミングの手法のようなもので今回は色分けする際のルールをあらわしています。
それではやって行きます!
わからない人はプログラミングでこんなことができるんだなというくらいの認識で大丈夫です。
デモデータの作成
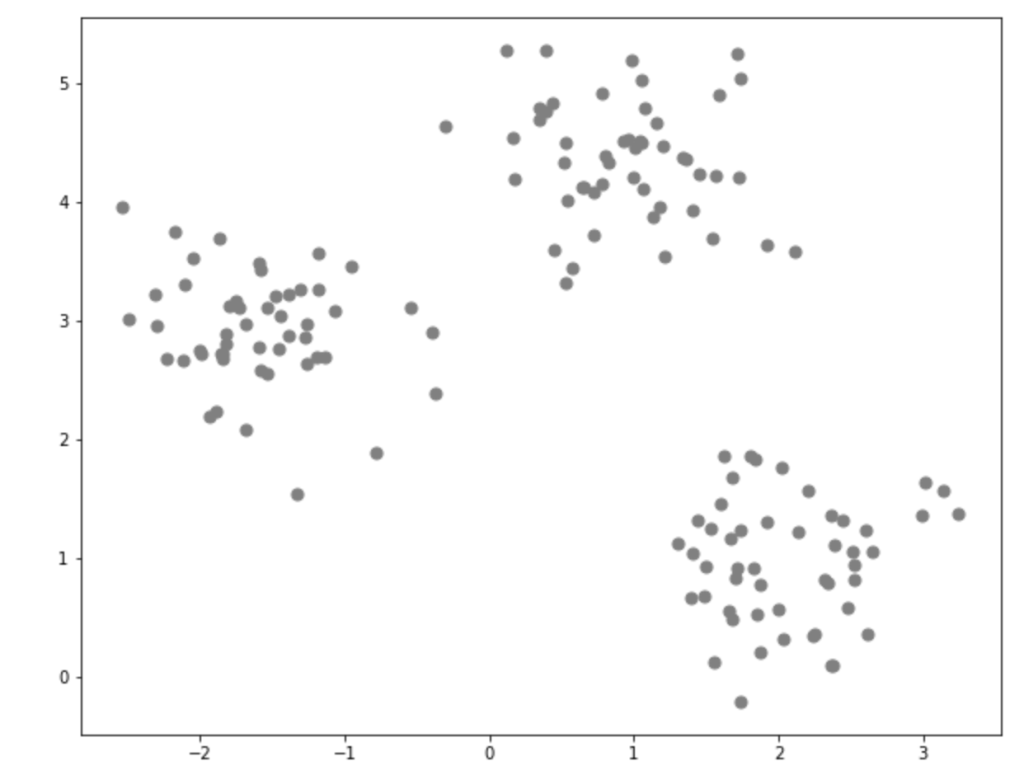
まずはクラスタリングするために今回はデータを作っていこうと思います。
sklearnというライブラリが便利なメソッドを提供してくれています。
from sklearn.datasets import make_blobs
X,y=make_blobs(n_samples=150, # サンプル点の総数
centers=3, # クラスタの個数
cluster_std=0.5,# クラスタ内の標準偏差
shuffle=True, # サンプルをシャッフル
random_state=0) # 乱数生成器の状態を指定
# 図のサイズを指定する
plt.figure(figsize=(10,8))
# 図を描画する
plt.scatter(X[:,0],X[:,1],c='gray',s=50)
# 図を表示する
plt.show()今回は150個のデータを三つのクラスタに分けたデータを作成しました。
それではここから機械学習を使ってクラスタリングしていこうと思います。
クラスタリングの実行
今回はクラスタリングで有名なKMeansというライブラリを使いました。
from sklearn.cluster import KMeans
# KMeansライブラリの設定
km = KMeans(n_clusters=3,
random_state=0)
# 今回のモデルにフィットさせる
y_km = km.fit(X)
# グラフの描画
for i in range(3):
plt.scatter(X[:,0],X[:,1],c=y_km.labels_)y_kmの中には1の点は黄色グループ、2の点は緑グループ、3の点は黄色グループ、、、、
などという情報が入っています。
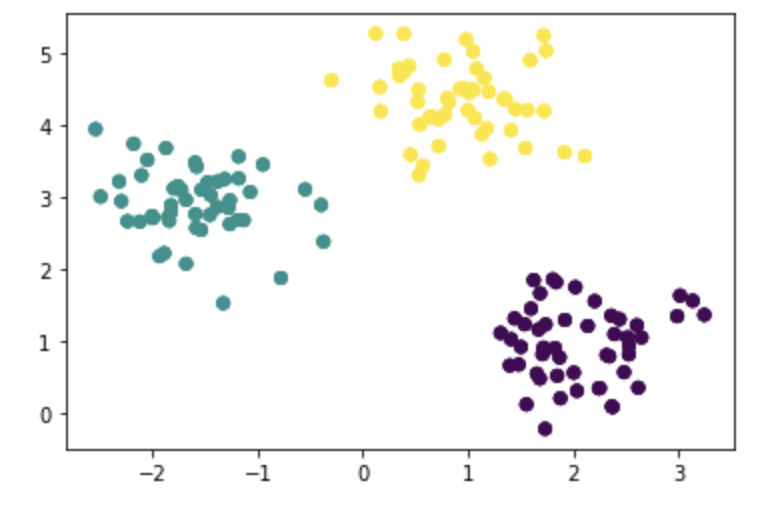
以下が実行結果です。
しっかりクラスタごとに色分けされているのが分かります。
今回はクラスタの数が3個でわかっていたけれど、何個かわからないときはどうすればいいの?
って思った方は鋭いです。
実は最適なクラスタの数を求める手法としてエルボー法という手法があります。
エルボー法についてはまたおいおい記事を出そうかなと思っています。
おわりに

今回は初心者の方向けに簡単にクラスタリングについて紹介、解説をしました。
一見簡単なように見えるクラスタリングですが突き詰めていけば実はとっても奥深いものです。
今回の記事がきっかけにデータサイエンスに興味がある方が少しでも増えてくれたら嬉しいです。
一緒に頑張って行きましょう。
ほかにもいろいろ投稿してるにゃ。



コメント