目次
はじめに

どーも、学生エンジニアのゆうき(@engineerblog_Yu)です。
今回はscikit-learnで提供されているボストン住宅価格データセットについて重回帰分析を行っていこうと思います。
今回の記事をお勧めする方は
データ分析に興味がある
scikit-learnを使ってみたい
データ分析コンペに出てみたい
に当てはまる人です。
今回の記事は以下の記事の続きとなっています。
重回帰分析について
今回は重回帰分析を行いますが、回帰分析にも色々な種類があります。
線形回帰
非線形回帰
の二つです。
これは単回帰分析で勉強したにゃ。
重回帰分析は線形回帰にあたります。
線形回帰
・単回帰分析
・重回帰分析
非線形回帰
・多項式分析
ここから具体的に単回帰分析との違いを説明します。
重回帰分析とは単回帰分析とは異なり、説明変数が2個以上あるものです。
つまり
$$y=ax_{1}+bx_{2}+cx_{3}\ldots$$
と表すことができます。
基本的に単回帰分析と考え方は同じで、最小二乗法などで誤差を最小にするということも同じです。
一つだけ単回帰分析と異なる点は、説明変数が3つ以上になると空間座標でも視覚化することができないという点です。
単回帰分析の場合では以下のようにグラフを書くことができましたが四次元以上になるとグラフを書くことができません。
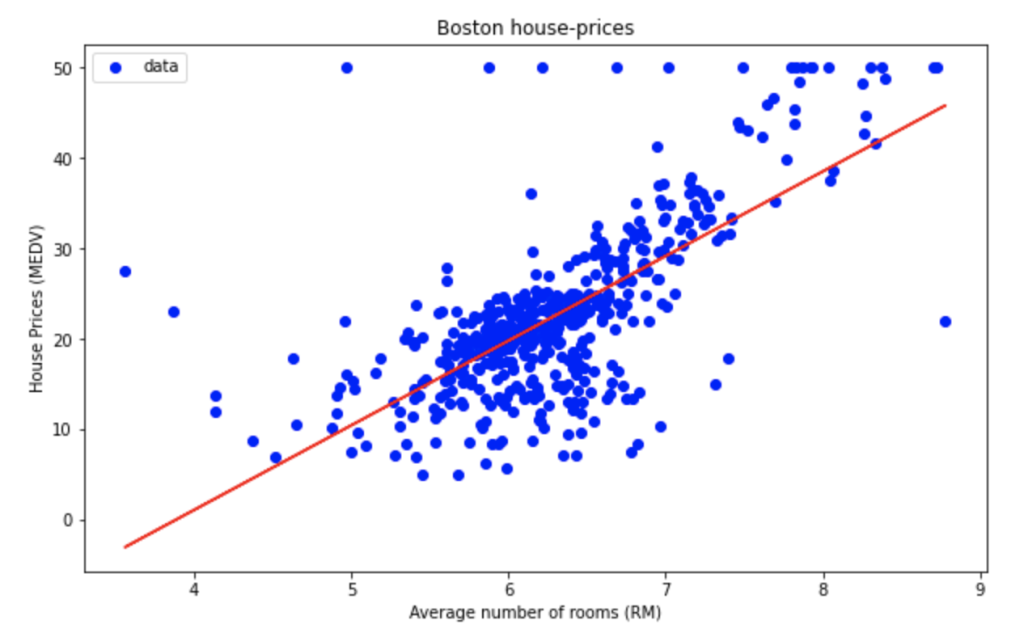
よって直感的に理解することが難しいのです。
目で見れないなんて不便にゃ。
でもやってることは単回帰分析と同じですので安心してください。
それでは実際に重回帰分析をやっていきましょう!
データセットの確認
今回使うボストンのデータはこのようになっています。(データ数は506件)
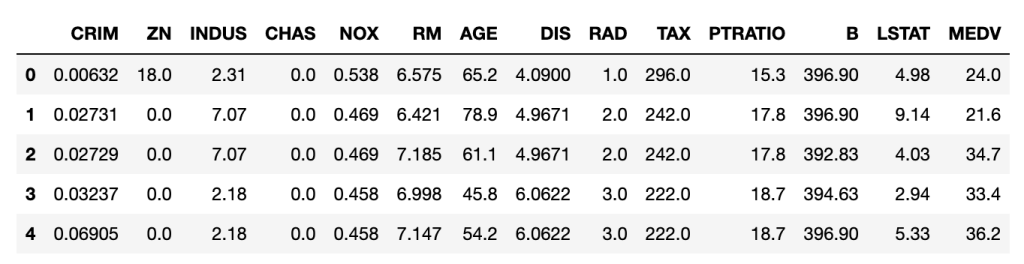
次にそれぞれのデータが何を意味するかについてです。
| カラム | 説明 |
| CRIM | 町ごとの一人当たりの犯罪率 |
| ZN | 宅地の比率が25000平方フィートを超える敷地に区画されている |
| INDUS | 町あたりの非小売業エーカーの割合 |
| CHAS | チャーリーズ川ダミー変数(川の境界にある場合は1,それ以外の場合は0 |
| NOX | 一酸化窒素濃度(1000万分の1) |
| RM | 1住戸あたりの平均部屋数 |
| AGE | 1940年以前に建設された所有専有ユニットの年齢比率 |
| DIS | 5つのボストンの雇用センターまでの加重距離 |
| RAD | ラジアルハイウェイへのアクセス可能性の指標 |
| TAX | 10000ドルあたりの税全額固定資産税率 |
| PTRATIO | 生徒教師の比率 |
| B | 町における黒人の割合 |
| LSTAT | 人口当たり地位が低い率 |
| MEDV | 1000ドルでの所有者居住住宅の中央値 |
今回は住宅価格に該当するMEDVの値をscikit-learnを使って予測し、どれくらいの精度なのか確かめていこうと思います。
データの取得

それではまずはデータの方を取得していきましょう。
以下のコードでsklearnの中にあるload_bostonというデータセットを読み込むことができます。
# データセットの取得
from sklearn.datasets import load_boston
dataset = load_boston()
# MEDV以外のデータ
x = dataset.data
# MEDV
t = dataset.targetまたdataset.dataはMEDV以外のデータを指し、dataset.targetはMEDVを指しています。
再度今回使用するデータを表示します。
上記のコードではxにMEDV以外のデータ、tにMEDVのデータを代入しています。
データセットの分割
次にデータセットの分割を行っていきます。
# データセットを分割する関数の読み込み
from sklearn.model_selection import train_test_split
# 訓練用データセットとテスト用データセットへの分割
x_train, x_test, t_train, t_test = train_test_split(x, t, test_size=0.3, random_state=0)train_test_splitについての説明です。
test_size=0.3と指定すると全データ中の30%がテストデータとなります。
またrandom_state=0とすることで実行するたびの分割を同じようにすることができます。(デフォルトでは実行するたびにランダムに分割されます)
重回帰分析をするためのモデルの定義

次にモデルの定義を行っていきます。
from sklearn.linear_model import LinearRegression
# モデルの定義
reg_model = LinearRegression()今回は線形回帰ですのでLinearRegressionを使います。
標準化

標準化に関する説明です。
データセットのばらつきが大きいときは特に、モデルを訓練させる前に標準化を行います。
標準化とはデータを平均0、分散1に統一するということです。
なぜ標準化が必要なのか気になる方も多いと思います。
例えば車の値段を重回帰分析を使って予測したいとします。
説明変数として耐久年数と車体重量があったとするとそれぞれの単位は(年)と(kg)です。
するとデータのばらつきがkgの方がもちろん大きくなり、平均も大きいので標準化を行わずに訓練すると精度が悪くなる場合があります。
今回もデータの標準化を行うために以下のコードを実行します。
# 標準化を行う
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(x_train)
x_train_scaled = scaler.transform(x_train)
x_test_scaled = scaler.transform(x_test)モデルの訓練

それでは訓練用データセットを用いてモデルをより良いものに訓練させていきましょう。
# モデルの訓練
reg_model.fit(x_train_scaled, t_train)この1行でモデルの訓練は完了です。
精度の検証

最後に精度を検証していきます。
以下のコードで精度を検証していきます。
# 精度の検証(訓練データ)
reg_model.score(x_train_scaled, t_train)Out[15]:0.7645451026942549
# 精度の検証(テストデータ)
reg_model.score(x_test_scaled, t_test)Out[16]:0.6733825506400195
スコアとして得られる数は決定係数の値です。
決定係数とは0から1の値をとり、1に近い値であればあるほどモデルの精度が良いものになっているといえます。
訓練データよりもテストデータの方が精度が低くなるのは当たり前なので前処理やモデルを改善することでどれだけ精度を高くしていけるかということが大切になってきます。
最後に予測値と実際の値の差をプロットしてみます。
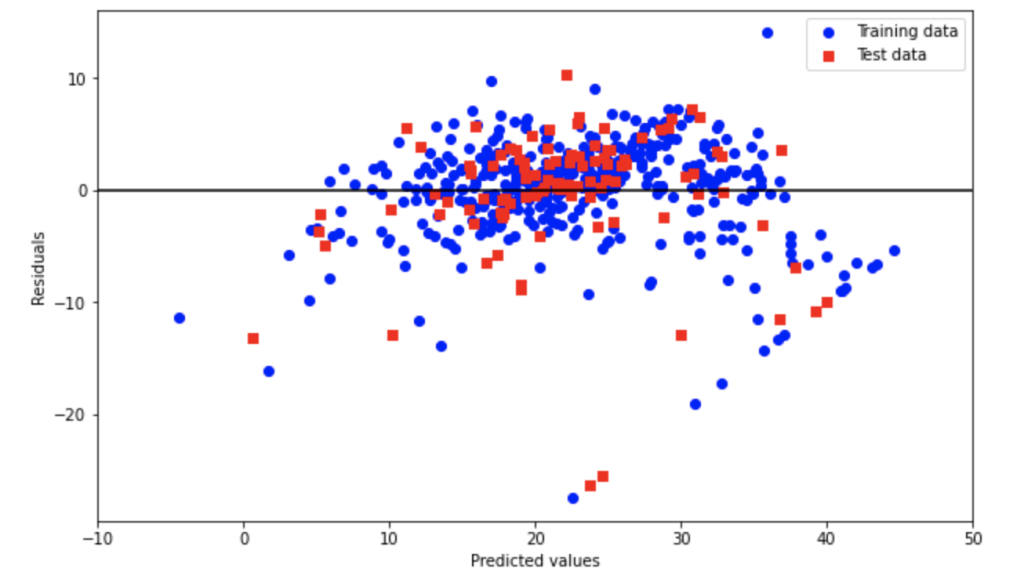
誤差が0付近に多くのデータが集まっていることがわかります。
今回の内容は以上です。
いかがだったでしょうか?
少ないコードで簡単に重回帰分析を行うことができるscikit-learnに感謝ですね。
最後に
- 機械学習をやってみたい
- データサイエンスに興味がある
- プログラミングのスキルを身につけたい
という方向けにおすすめの講座を紹介したいと思います。
【おわりに】データサイエンスお勧め勉強法
結論から言うとUdemyというオンライン学習サービスのこちらの講座がおすすめです。
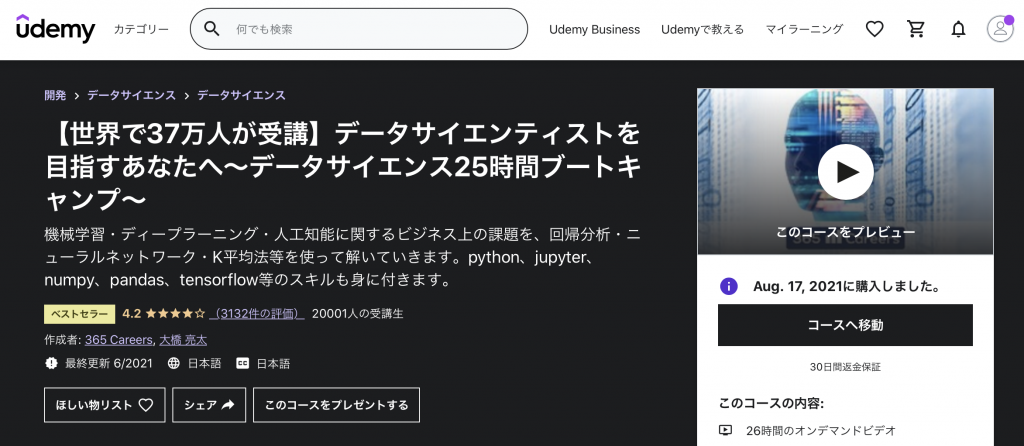
こちらの動画ではデータサイエンティストになるためのロードマップからそれぞれの分野について映像を用いた分かりやすい説明がなされています。
データサイエンスには以下の三つのスキルが必要と言われています。
- ビジネススキル
- 数学スキル
- プログラミングスキル
この講座を受けると
・大学数学をあまり理解できていない
・プログラミングにあまり触れたことがない
・ビジネス経験がない
という方でも総合的な理解を深めて未経験からデータサイエンティストになることも可能だと思います。
スキルを身につけて安定を得たい、プログラミングの副業をやってみたいという方に特におすすめの講座です。
一緒に頑張っていきましょう。
他にもいろんな記事を投稿してるにゃ。



コメント