目次
はじめに

こんにちは。学生エンジニアのゆうき(@engieerblog_Yu)です。
今回は主成分分析を用いて以前私が行ったワイン分類の正確率を上げていこうと思います。
今回の記事をお勧めする方は
データ分析に興味がある
scikit-learnを使ってみたい
機械学習を使って分類問題を解いてみたい
kaggleに挑戦したい
と思っている人です。
また今回の記事は以下の記事の続きとなっています。
説明を省略させていただいた部分もあるのでこちらの記事を先に読むことをお勧めします。

教師なし学習について

教師あり学習とは正解データが事前に用意されているものです。
反対に教師なし学習であれば正解データは事前に用意されていません。
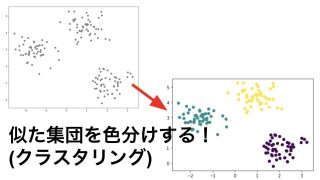
主成分分析は教師なし学習に分類され、教師なし学習には主に以下の二つのものがあります。
【教師なし学習】
・クラスタリング
・次元削減(この中に主成分分析が含まれる)
教師あり学習については以下のものが含まれます。
【教師あり学習】
・回帰問題
・分類問題
今回行うものは教師なし学習の次元削減ということをしっかり理解していただきたいと思います。
ちょっとややこしくなる話をします。
今回は分類問題を解きたいので教師あり学習の分類問題を解く手法としてロジスティック回帰を使っています。
その過程で教師なし学習の次元削減の手法である、主成分分析を使っているということに気をつけてください。
なんとなくわかったにゃ。
なぜ次元削減を行うか?

まずは次元削減をなぜ行うかについて説明をしようかなと思います。
データ分析において多次元のデータを処理しようと思うと計算量が膨大になることが多々あります。
例えば今回用いるワインのデータセットだと特徴量が13列あります。
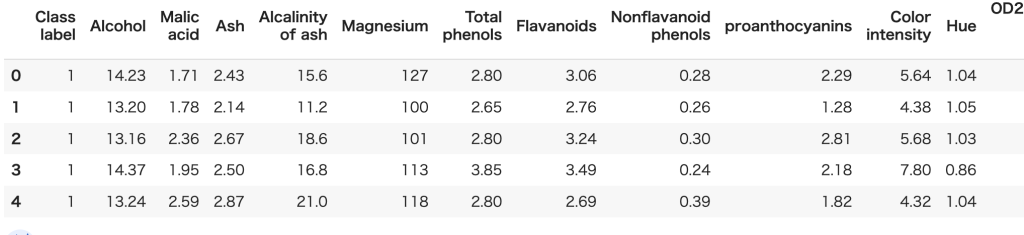
つまり全ての特徴量を使おうと思うと、13次元で考えなければならないのです。
これは一般に計算を行うのは大変になります。
そこでどうやって計算量を減らすかと言うことを考えなければなりません。
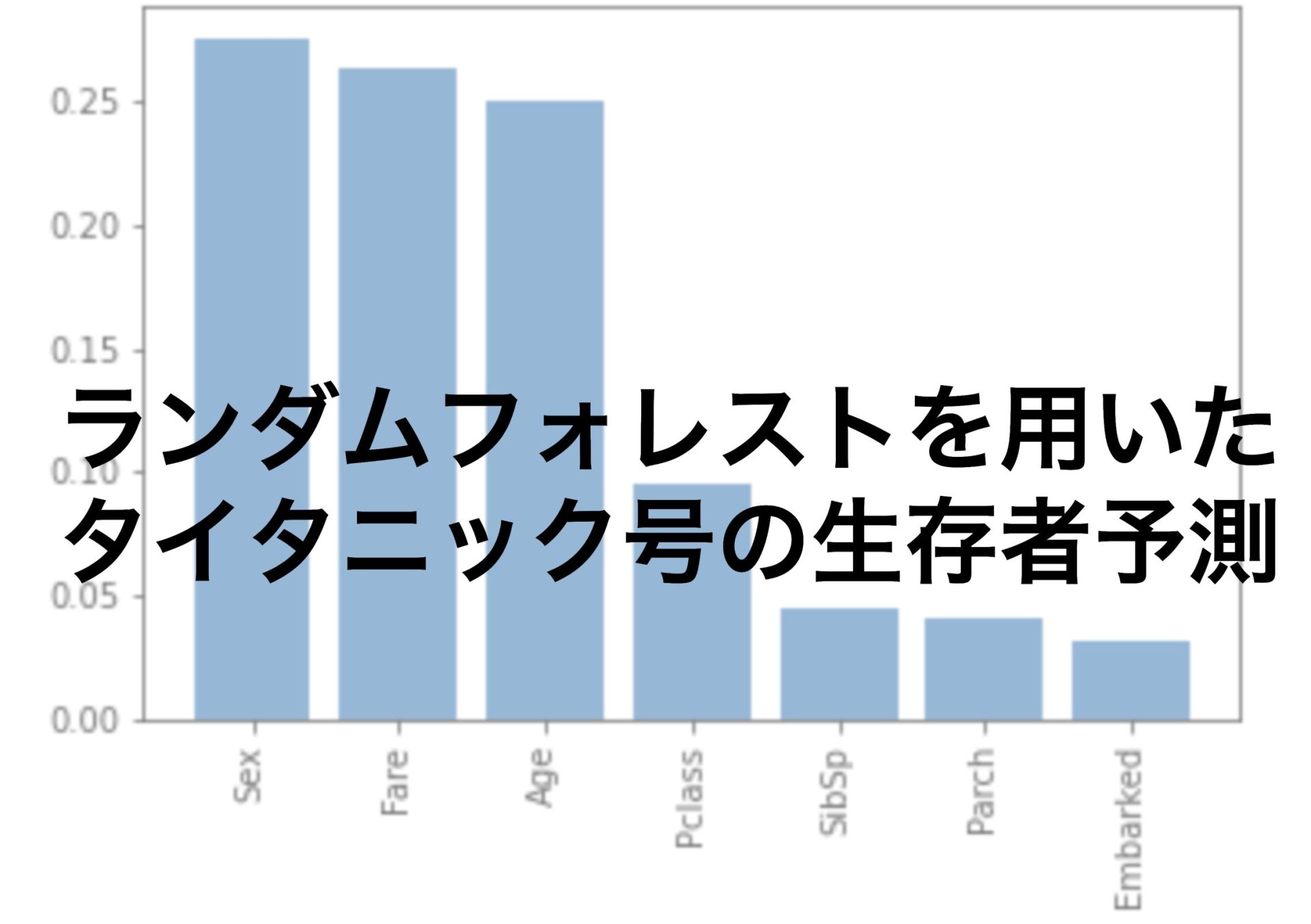
一つは以前の記事でも紹介しているランダムフォレストです。
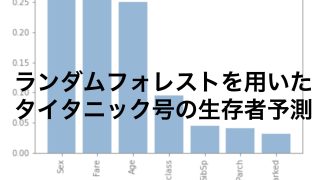
ランダムフォレストを使うことで特徴量の重要度を評価してくれます。
これで重要な特徴量を抜き出すことができます。
もう一つのアプローチが次元削減です。
次元削減では多次元のデータをできるだけ情報を損わずに低次元にするということを考えます。
その次元削減の手法の一つが主成分分析です。
次元削減は多次元のデータの情報をできるだけ損わずに、低次元にするという手法
主成分分析について
それでは主成分分析についてです。
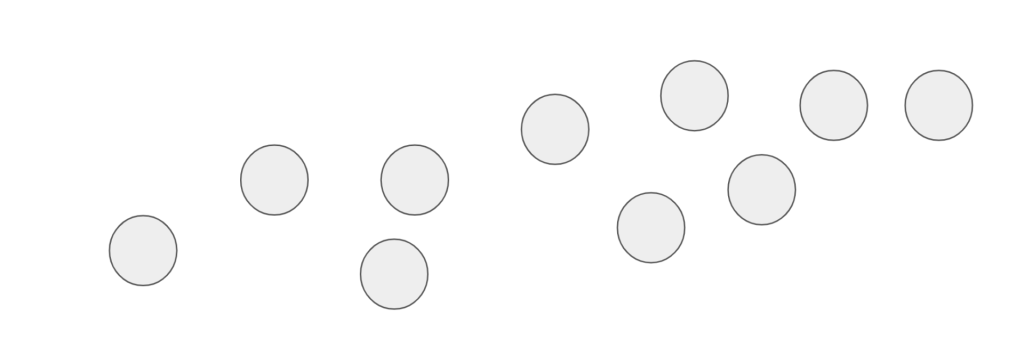
今回は簡単のために二次元データを一次元データに削減することを考えます。
二次元空間上にこのようなデータがあります。
このデータの情報をできるだけ損わずに一次元データにすることを目的とします。
一次元にしたときのデータの散らばり(分散)が最も大きくなる軸を求めます。
わからなくなってきたにゃ。
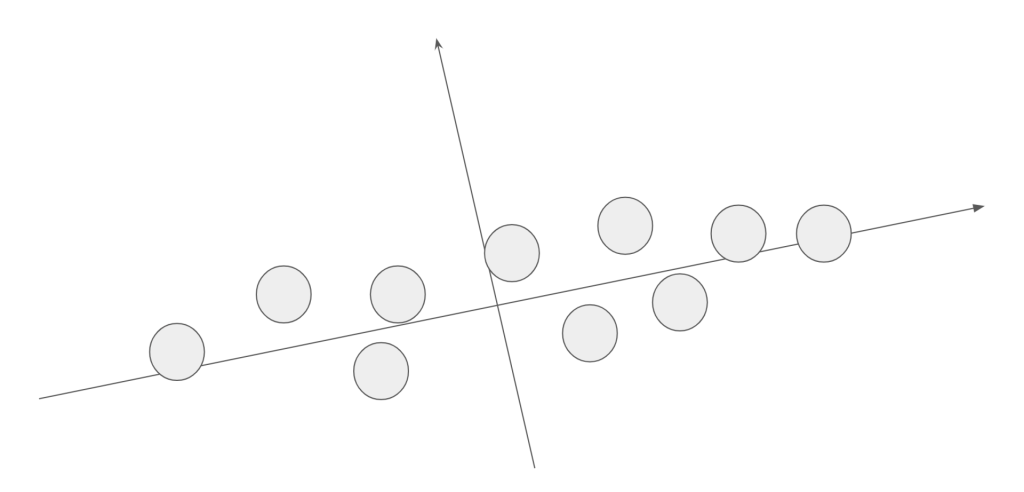
計算によりこのような軸が定められたとします。
次にこのデータを射影し、一次元にします。
このとき射影した軸を第一主成分と言います。(第一主成分に垂直な軸は第二主成分)

一次元にしたときにデータの散らばりが最も大きくなるように軸を考えているので、情報が損なわれている量を減らしていると考えられます。
一般に多次元に拡張しても行列演算を行うことで主成分分析を行うことができます。
主成分分析ではデータの分散が最も大きくなるように、軸にデータを射影する
それでは主成分分析を実際にやっていきましょう!
今回の記事のメインは主成分分析ですので、それ以外の部分は以前の記事に解説してあります。
さぼりたい気持ちをすごく感じるにゃ。
ライブラリのインポート
今回用いるライブラリは以下です。
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from mlxtend.plotting import plot_decision_regions
from sklearn import datasets
from sklearn.decomposition import PCA データセットの準備と標準化
それではscikit-learnで提供されているワインデータセットを準備していきます。
wine = datasets.load_wine()
X = wine.data
y = wine.target
#訓練用データとテストデータに分割
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=0)
#特徴量の標準化
sc = StandardScaler()
X_train_std = sc.fit_transform(X_train)
X_test_std = sc.transform(X_test)今回は訓練用データとテストデータを8:2で分割しました。
主成分分析を行う
それではメインの主成分分析です。
主成分分析のモデルを作成してから標準化したデータを入れてあげましょう。
n_componentsで削減後の次元数を指定しています。
PCA = PCA(n_components=2)
X_train_pca = PCA.fit_transform(X_train_std)
X_test_pca = PCA.transform(X_test_std)以下では因子寄与率を求めることができます。
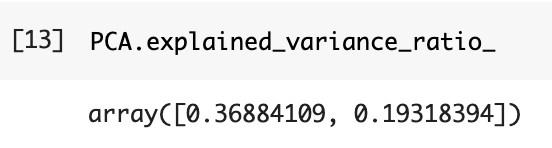
第2主成分までで約0.37+0.19で0.56ですので元情報の約56%を保持していることがわかります。
またしっかり13次元だったものが2次元に削減されていることがわかります。


ロジスティックモデルの作成
次にロジスティックモデルを作成します。
| max_iter | 勾配降下法を行う回数 |
| multi_class | 多クラス分類の方法を’ovr’,’multinomial’,’auto’から選ぶ |
| solver | 計算に使用するライブラリ |
| C | 正則化の強さを表し、値が大きいほど正則化の効果は弱くなる |
| penalty | 正則化を’l1′,’l2′,’elasticnet’から選択 |
| l1_ratio | elasticnetを選んだ時のl1正則化の割合を指定する |
| random_state | 乱数のシードを指定 |
# ロジスティックモデルの作成
logistic_model = LogisticRegression(max_iter=100,multi_class='ovr',solver='liblinear',C=1.0,penalty='l2',l1_ratio=None,random_state=0)
logistic_model.fit(X_train_pca,y_train)モデルの評価
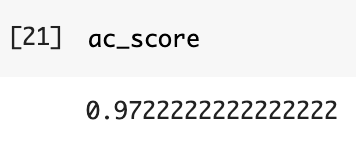
それではモデルを評価していきます!
# 予測値の作成
y_test_pred = logistic_model.predict(X_test_pca)
# 正確率の計算
ac_score = accuracy_score(y_test,y_test_pred)主成分分析の結果97%の正確率で分類を行うことができました。
これはすごいにゃ。
訓練データのプロット
最後にどのようにモデルが作成されているのか可視化していきます。
# 訓練データのプロット
plt.figure()
plot_decision_regions(X_train_pca,y_train,logistic_model)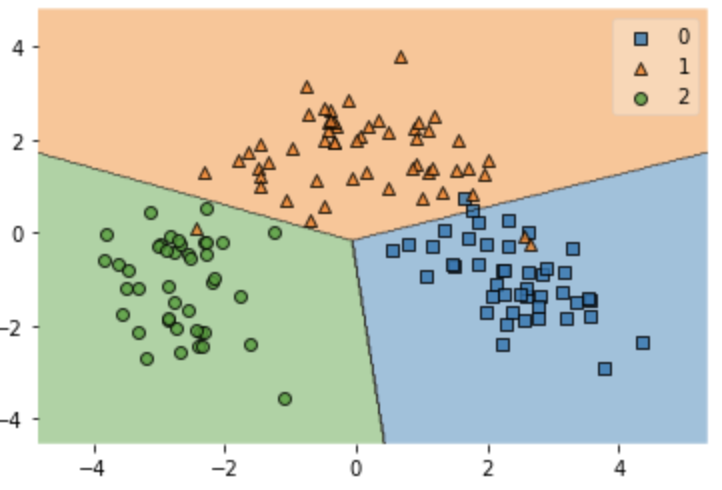
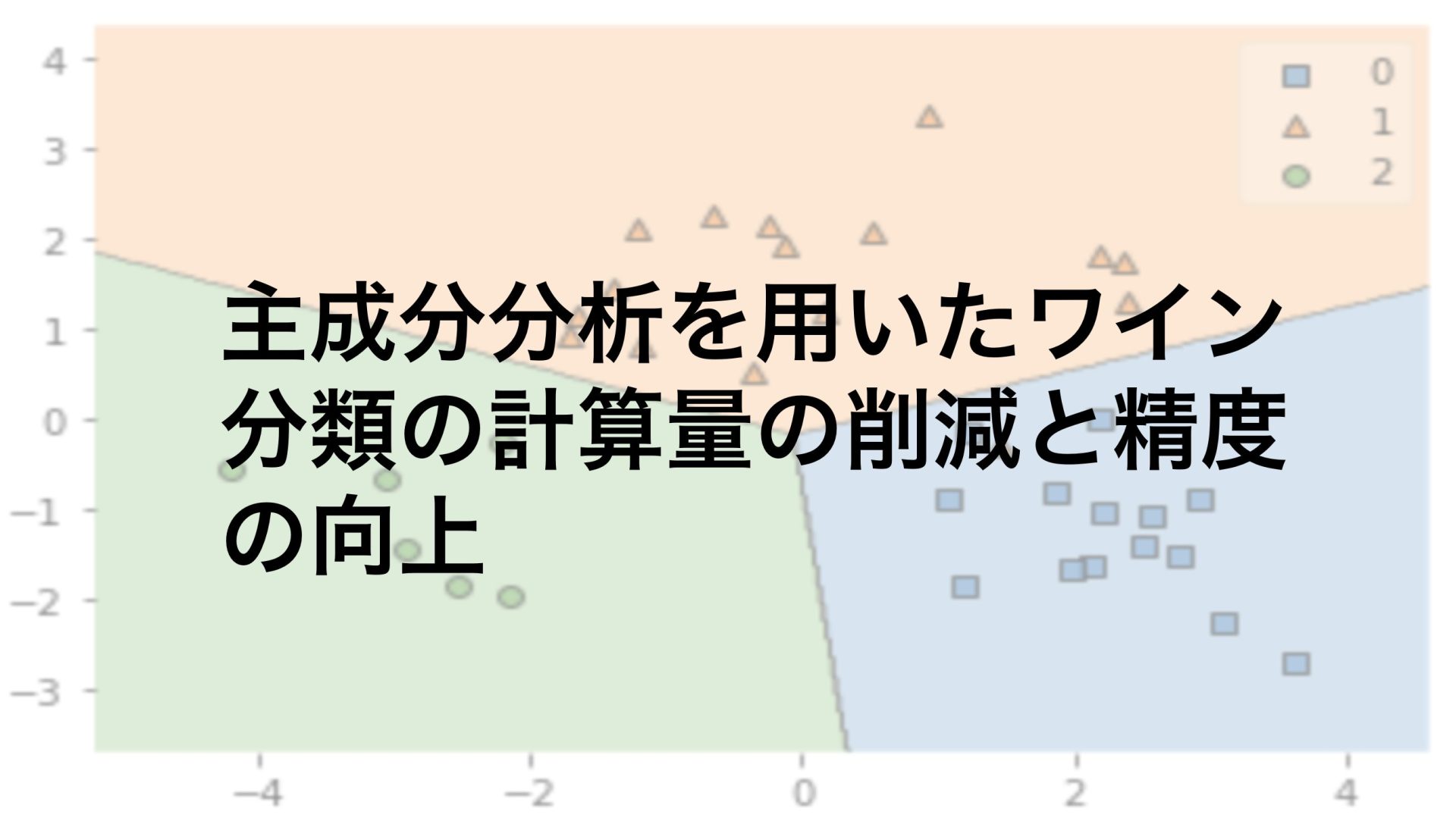
テストデータのプロット
# テストデータのプロット
plt.figure()
plot_decision_regions(X_test_pca,y_test,logistic_model)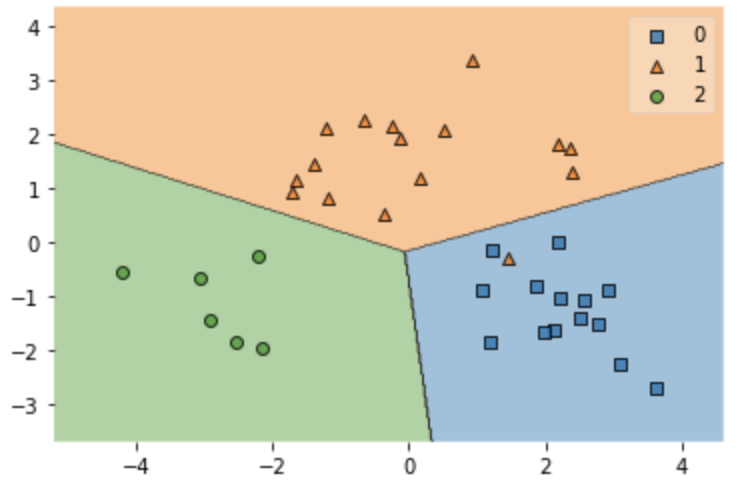
オレンジ色の三角の点を除いて正しく分類することができていることがわかります。
おわりに

今回は前回の記事の続きとしてワイン分類を主成分分析を使って精度を上げていきました。
データサイエンスを楽しんでいただけるきっかけになれば嬉しいです。
他にもいろんな記事があるにゃ。

コメント