目次
はじめに
こんにちは。将棋と筋トレが好きな、情報系大学生のゆうき(@engieerblog_Yu)です。
今回はニューラルネットワークの重みの初期値設定で使われるXavierの初期値・Heの初期値についてまとめていきたいと思います。
重みパラメータの値が大きい=過学習
前回の記事でも述べましたが、ニューラルネットワークで学習したいパラメータの一つに、重みがあります。

重みを学習しすぎてしまうと値が大きくなってしまい、過学習になってしまいます。
ニューラルネットワークの学習モデルの汎化性能を高めるためには、重みが大きくなりすぎないことが大切です。
ニューラルネットワークの学習モデルの汎化性能を高めるためには、重みが大きくなりすぎないことが大切
重みを大きくさせないためには初期値も小さくした方が良い
学習後の重みパラメータの値が大きくなりすぎないためには、重みの初期化に気を払わなければなりません。
具体的には、重みの初期パラメータを小さくする必要があります。
しかしここで疑問が生じます。
初期パラメータはどれくらい小さくすれば良いのか?
全て0ではダメなのか?
といったものです。
次にこの疑問についてまとめていきます。
重みの初期値を全て均一の値にしてはいけない
結論ですが、先ほどの全て0ではダメなのか?という疑問に対しての答えは「ダメ」です。
重みの初期値を全て均一の値にしてしまうと、順伝播の過程で全て同じ値が入力されてしまいます。
これでは重みをたくさん設定するために、ニューラルネットワークを大きくした意味がなくなってしまいます。
一般に重みをバラつかせるために、ランダムな初期値を設定することが必要とされています。
重みパラメータの初期値は、ランダムに設定する必要がある
重みの初期値はどれくらい小さくすればいいのか?
重みの初期値はどれくらい小さくすればいいのか?という疑問に対しての、現状の最適解はXavierの初期値・Heの初期値を用いるということです。
それぞれの詳細を説明していきます。
Xavierの初期値
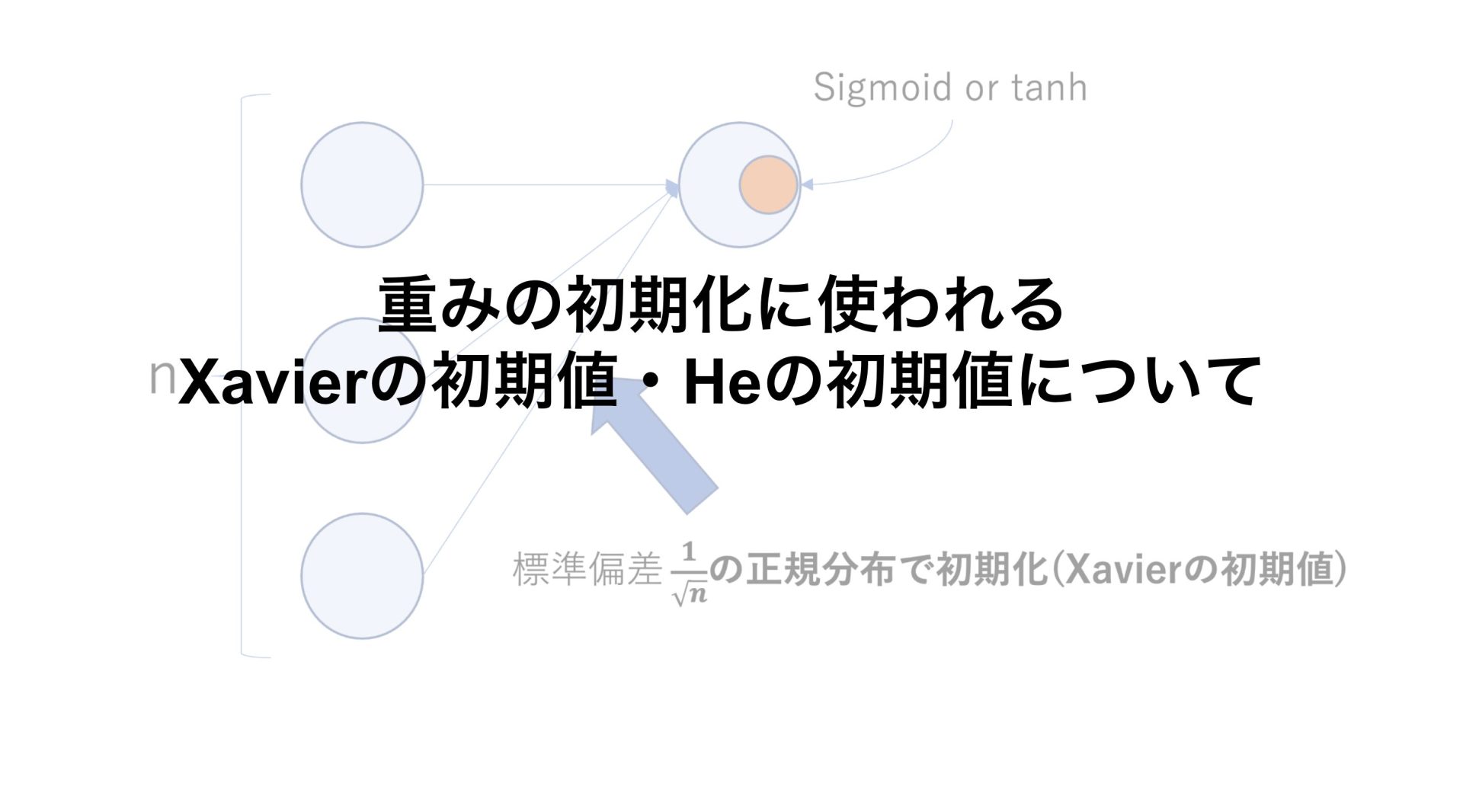
Xavierの初期値とは活性化関数がSigmoidかtanhである場合に使われます。
重みの初期値を\(\frac{1}{\sqrt{n}}\)の標準偏差を持つ正規分布で初期化するというものです。
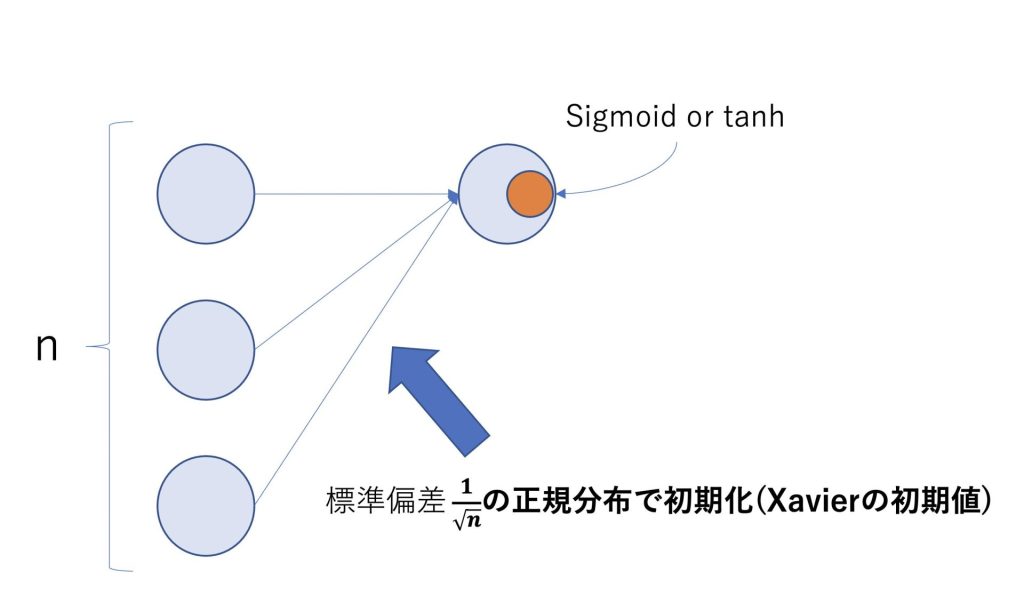
活性化関数がSigmoidかtanhであれば、Xavierの初期値を使うのが良いとされている
Xavierの初期値は活性化関数が線形である場合に使われ、Sigmoidとtanhは中央付近で線形近似を行うことができるので相性がいいということになります。
Xavierの初期値を使うことで適度に広がりを持ったデータをニューラルネットワークに流すことができます。
Heの初期値
Heの初期値とは活性化関数がReLUである場合に使われます。
重みの初期値を\(\sqrt{\frac{2}{n}}\)の標準偏差を持つ正規分布で初期化するというものです。
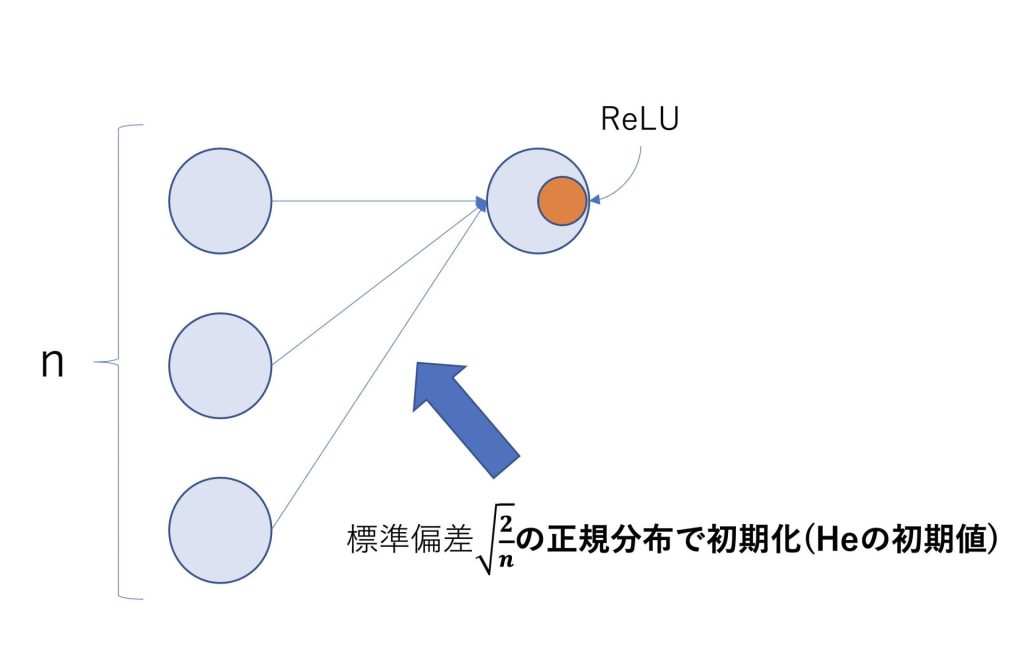
活性化関数がReLUであれば、Heの初期値を使うのが良いとされている
まとめ
ニューラルネットワークの学習モデルの汎化性能を高めるためには、重みが大きくなりすぎないことが大切
重みパラメータの初期値は、均一でないランダムな値に設定する必要がある
活性化関数がSigmoidかtanhであれば、Xavierの初期値を使うのが良いとされている
活性化関数がReLUであればHeの初期値を使うのが良いとされている
今回はニューラルネットワークの重みの初期化に使われるXavier・Heの初期値についてまとめました。
機械学習、ディープラーニングを学びたい方におすすめの入門書籍です。
ディープラーニングの理論が分かりやすくまとめられていて、力を身につけたい方におすすめです。
最後まで読んでいただきありがとうございました。
他のおすすめ記事にゃ。


AI美女生成に興味がある方
Stable Diffusionを使ってAI美女を生成する方法についてもnoteで解説しています。

ChatGPT技術に興味がある方
完全版noteで、ChatGPTのおすすめChrom拡張機能5つと収益化方法について解説しています。
完全版noteでは、以下について解説しています。
Googleスプレッドシートやドキュメントの自動入力
ツイートの自動返信
Youtube動画の自動要約
Gmailの自動返信
検索画面にChatGPTの結果表示

コメント