
初めに
こんにちは。将棋と筋トレが好きな、情報系大学生のゆうき(@engieerblog_Yu)です。
今回は、ニューラルネットワークの明示的な正則化についてまとめていきたいと思います。
正則化とは?
ニューラルネットワークを学習しすぎてしまうと、訓練誤差が小さくなるのと対照的に、汎化誤差が大きくなってしまうことがあります。
そのようなことを過学習と言います。
正則化は過学習を防ぐために行われるものです。
正則化には明示的な正則化と隠的正則化があります。
明示的な正則化は人為的に行われるもので、それに対して隠的正則化はニューラルネットワークのモデルを学習する過程で勝手に行われるものです。
隠的正則化については以下の記事でまとめてあります。

今回は、明示的な正則化についてです。
明示的な正則化は、主に三つあります。
・データオーグメンテーション
・Weight Decay
・Dropout
です。
一つ一つまとめていきます。
正則化は過学習を防ぐために行われるもの
正則化には明示的な正則化と隠的正則化がある
明示的な正則化にはデータオーグメンテーションとWeight Decay、Dropoutの三つがある
データオーグメンテーション
データオーグメンテーションは、入力xに対して出力yがただ一つに定まるような問題に使われる手法です。
例えば画像分類や音声認識などが挙げられます。
データオーグメンテーションを一言で表すと、入力を出力結果を変えない程度で変換し、データを水増しするような手法です。
具体的に画像分類で考えると、犬と猫の分類問題があったとします。
入力である猫の画像を入れると、「これは猫です」と返してくれるモデルを作成したい訳です。
しかし入力である猫の画像が少なかったり、特徴が偏っていたりすると汎化性能が低いモデルを作成してしまう可能性があります。
そこで猫の画像を平行移動や、回転処理、色の変更などをおこなって、データを増やすことで汎化性能を上げようというのがデータオーグメンテンションです。

データオーグメンテンションでは変換処理を組み合わせることでも汎化性能を向上することができ、非常に有効な正則化の手法です。
データオーグメンテンションとは入力に変換処理を行い、データの水増しを行うような手法
Weight Decay
ニューラルネットワークの過学習の原因の一つとして、重みパラメータが大きくなりすぎてしまうというものがあります。
そのような重みパラメータが大きくなりすぎないようにする工夫の一つにWeight Decayがあります。
Weight Decayでは、損失関数に重みのL2ノルムを加算します。
そうすることで、大きな重みを持つことにペナルティを課して、重みパラメータを小さくすることができます。
L2ノルムは以下のように表されます。
\(\sqrt{w_1^2+w_2^2+・・・w_n^2}\)
\(W = (w_1,w_2,・・・・w_n)\)
Weight Decayとは、損失関数に重みのL2ノルムを加算し、重みパラメータが大きくなりすぎないようにする手法
Dropout
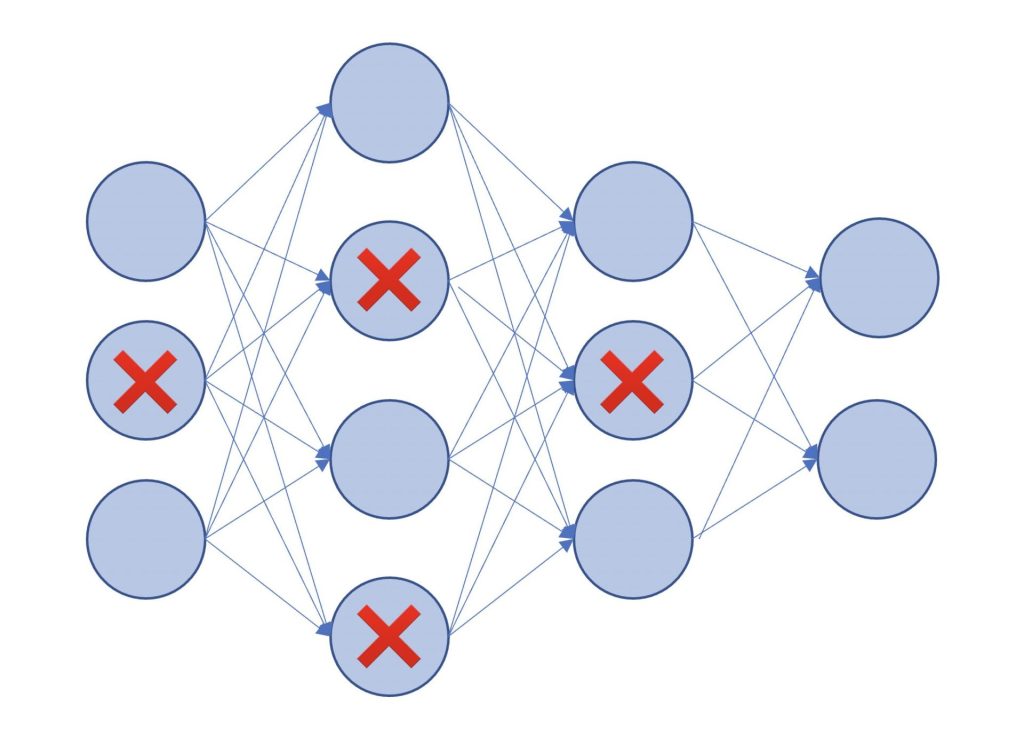
Dropoutは、ニューラルネットワークのノードをランダムに消去しながら学習を進めるという手法です。
Dropoutは、ニューラルネットワークのモデル学習時のニューロンをランダムに消去することで毎回異なるモデルを学習していると考えることができます。
よって訓練データの精度が高くなりにくく、それに合わせて訓練誤差と汎化誤差の差が小さくなりやすくなります。
表現力が高いニューラルネットワークでも、過学習が起こりにくく、汎化誤差を小さくすることができます。
Dropoutはニューラルネットワークのノードをランダムに消去しながら学習を進めるという手法
まとめ
データオーグメンテンションとは入力に変換処理を行い、データの水増しを行うような手法
Weight Decayとは、損失関数に重みのL2ノルムを加算し、重みパラメータが大きくなりすぎないようにする手法
Dropoutはニューラルネットワークのノードをランダムに消去しながら学習を進めるという手法
今回はニューラルネットワークの明示的な正則化についてまとめました。
機械学習、ディープラーニングを学びたい方におすすめの入門書籍です。
ディープラーニングの理論が分かりやすくまとめられていて、力を身につけたい方におすすめです。
最後まで読んでいただきありがとうございました。
他のおすすめ記事にゃ。


コメント