目次
初めに
こんにちは。将棋と筋トレが好きな、情報系大学生のゆうき(@engieerblog_Yu)です。
今回は私の研究内容である、サロゲートモデルについての記事です。
サロゲートモデルとは?
サロゲートモデルとは、シミュレーション代理モデルのことで、物理モデルの代わりに深層学習を用いて物理プロセスを計算します。
物理モデルは、支配方程式(複雑な偏微分方程式)で構成されます。

inputを入れると、それに応じてシミュレーションを行なってoutputを出力します。
しかし物理モデルを使ったシミュレーションには問題点があります。
物理モデルを使うと計算結果が正確である反面、計算コストがかかります。
大規模なシミュレーションになってくると、シミュレーションを一回行うごとに、2,3日の時間がかかることもあります。
そこで考案されたのが、シミュレーションの代理モデル(サロゲートモデル)です。
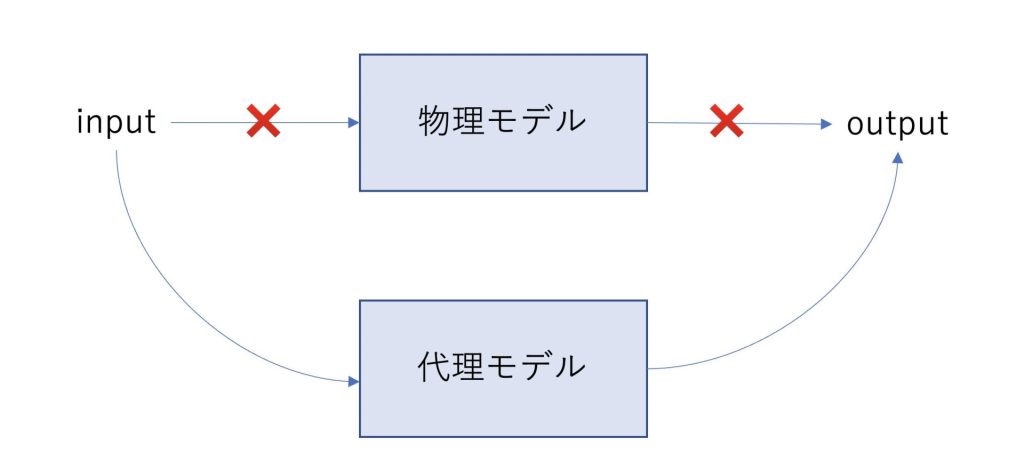
サロゲートモデルは物理モデルの代わりに、深層学習で物理プロセスを計算します。
inputとoutput(訓練データ)の組み合わせからサロゲートモデルを構築し、新しいinputに対してoutputを出力することができます。
サロゲートモデルを構築することで、これまで2,3日かかっていたシミュレーションが数秒で完了することができる可能性があります。
サロゲートモデルを用いることでシミュレーション時間を大幅に短縮することができる

サロゲートモデルの課題
しかし便利そうなサロゲートモデルにも多くの課題があります。
課題の一つとして、入力データが大きい場合、モデルの学習にかかる時間コストが大きくなってしまうことです。
シミュレーションの入力データと出力データをそのまま学習しようと思うと、何億年かかってしまうなんて可能性もあり得ます。
GPUなどを用いて計算速度をあげることも考えられますが、それだけでは限界があります。
そのために、色々な工夫してデータを削減することが必要です。
データの削減手法の一つとしてVDL-Surrogateというものがあるので紹介していきます。
入力データが大きすぎた場合、モデルの学習コストを小さくする工夫を考えなければならない
VDL-Surrogateモデルについて
今回紹介する内容は以下に基づいています。
VDL-Surrogate: A View-Dependent Latent-based Model for Parameter Space Exploration of Ensemble Simulations
https://arxiv.org/abs/2207.13091
VDL-SurrogateとはA View-Dependent Latent-based Surrogate Modelの略で、ビュー依存の潜在表現をベースとしたサロゲートモデルと訳すことができます。
データ削減手法と潜在的表現の抽出
まずはVDL-Surrogateがどのようにデータを削減しているかについてまとめていきます。
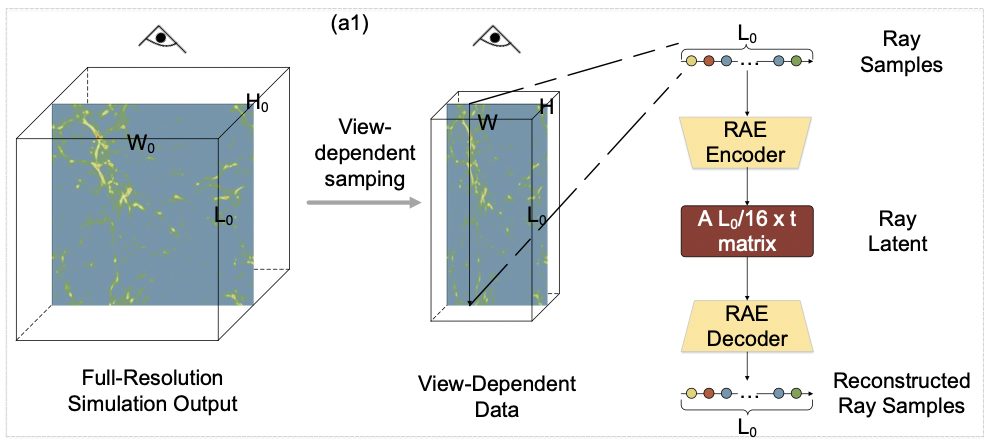
まず\(W_0×H_0×L_0\)のシミュレーションの出力があります。(Full-Resolution Simulation Output)
次に視点方向に垂直な平面(W×H)を適切な解像度に切り取ります。(View-Dependent Data)
視点方向に並行な\(L_0\)個のデータをRay Sampleとして取得して、RAE Encoderにインプットします。
RAE Encoderから出力される値(Ray Latent)はRay Sampleの特徴をよりコンパクトに表しているようなデータです。
Ray LatentをRAE Decoderにインプットさせると再構築されたRay Sampleを取得することができます。
次に、Ray Latentを出力とするVDL-Predicterを学習していきます。
VDL-Predicterの学習
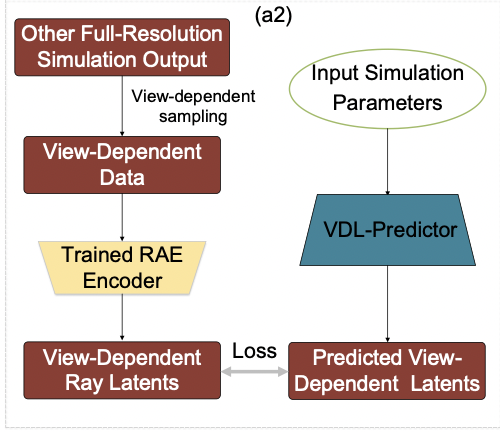
VDL-Predicterは、シミュレーションの入力パラメータと、先ほどのRay Latentsの組をセットにして学習されます。
VDL-Predicterにシミュレーションの入力パラメータを入れると、Ray Latentsに近い値を返すことが目標です。
VDL-Surrogateモデルの実行
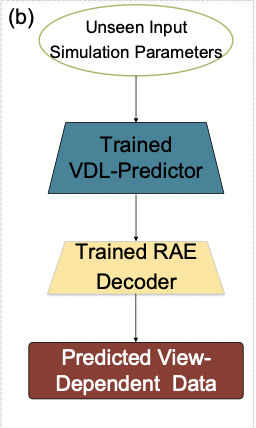
先ほどの過程で学習されたVDL-Surrogateは新しいシミュレーション入力で試されます。
VDL-Surrogateモデルの出力はRay Latentsを予測します。
Predicted-Ray LatentsをRAE Decoderに入力すると、適切な解像度に設定されたシミュレーション出力(View-Dependent Data)を再構築することができます。
VDL-Surrogateモデルの精度
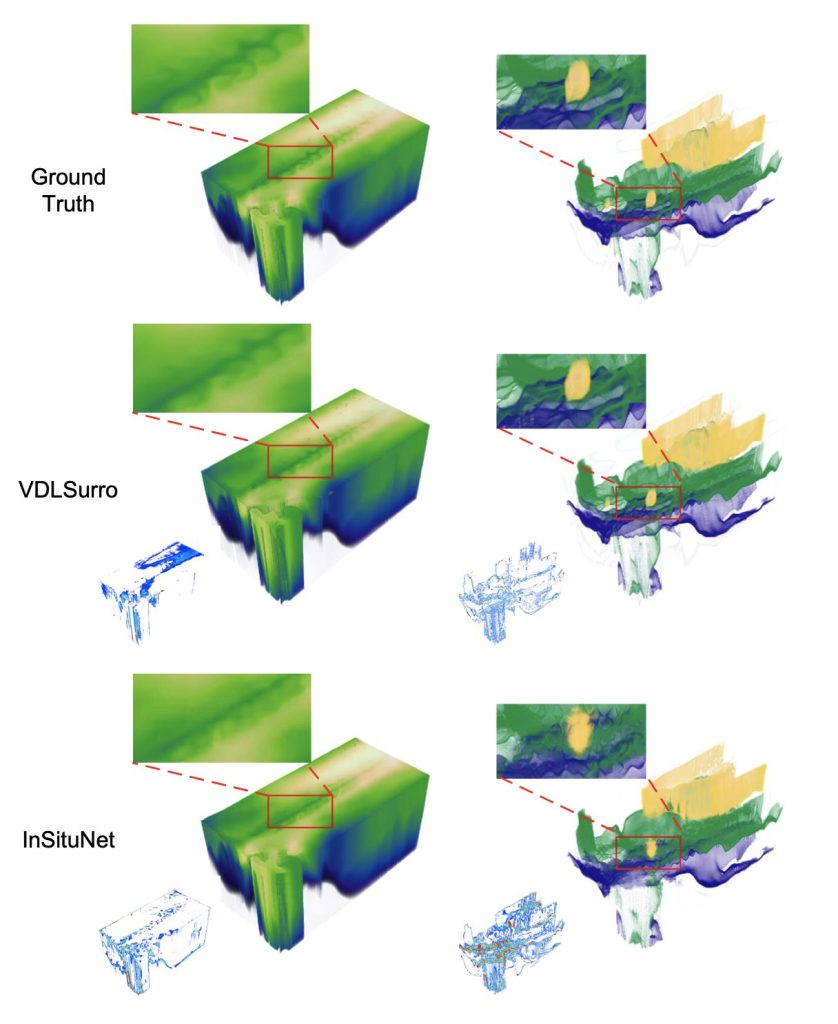
作成されたVDL-Surrogateモデルの精度についてです。
可視化されたものを見ると、InSituNetよりもVDL-Surrogateモデルの方がよりシミュレーション出力を再現することができていることがわかります。
VDL-Surrogateモデルの課題
筆者はVDL-Surrogateモデルの課題として以下を述べています。
視点を三つからしか選ぶことができない(任意の場所にしてしまうとデータが立方体で無くなってしまうため
モデルの学習に約50時間かかってしまった
任意の場所にある視点に対応するためにGNN(グラフニューラルネットワーク)の適用も考えているそうです。
またGPUなどを用いたさらなるモデルの高速化なども視野に入れているそうです。
感想
約50時間のモデルの学習のみでここまでシミュレーション出力を予測できるのか!とびっくりしました。
視点を三つだけでなく、任意の視点で選べるようになればさらなる精度の向上が見込めそうな手法で画期的だと感じました。
サロゲートモデルはまだまだ研究途中ですので、これからを最新情報を追っていこうと思います!
著者の方は画像ベースのサロゲートモデルである、InSituNetについても提案しているので、そちらも簡単にまとめました。
最後まで読んでいただきありがとうございました。
より詳細が知りたい方は元論文をどうぞ。
VDL-Surrogate: A View-Dependent Latent-based Model for Parameter Space Exploration of Ensemble Simulations
https://arxiv.org/abs/2207.13091
関連記事にゃ。



コメント