
目次
初めに
どーも、将棋と筋トレが好きな学生エンジニアのゆうき(@engieerblog_Yu)です。
今回は、PyTorchでAlexNetを構築して、CIFAR-10の画像分類をやっていこうと思います。
今回はGoogle Colaboratoryで、GPUを使って実行しています。

CIFAR-10とは?
CIFAR-10とは、動物や乗り物のカラー画像が6万枚含まれているデータセットで、以下の種類の画像が含まれています。
- ラベル「0」: airplane(飛行機)
- ラベル「1」: automobile(自動車)
- ラベル「2」: bird(鳥)
- ラベル「3」: cat(猫)
- ラベル「4」: deer(鹿)
- ラベル「5」: dog(犬)
- ラベル「6」: frog(カエル)
- ラベル「7」: horse(馬)
- ラベル「8」: ship(船)
- ラベル「9」: truck(トラック)
今回はCIFAR-10を入力として、正解ラベルを出力するような画像分類モデルを、AlexNetで作っていきたいと思います。
今回やること
今回の目標は、与えられた画像をうまく分類できるようなモデルを作ることです。
そのようなモデルを作るためには、訓練と評価の二つのステップが必要です。
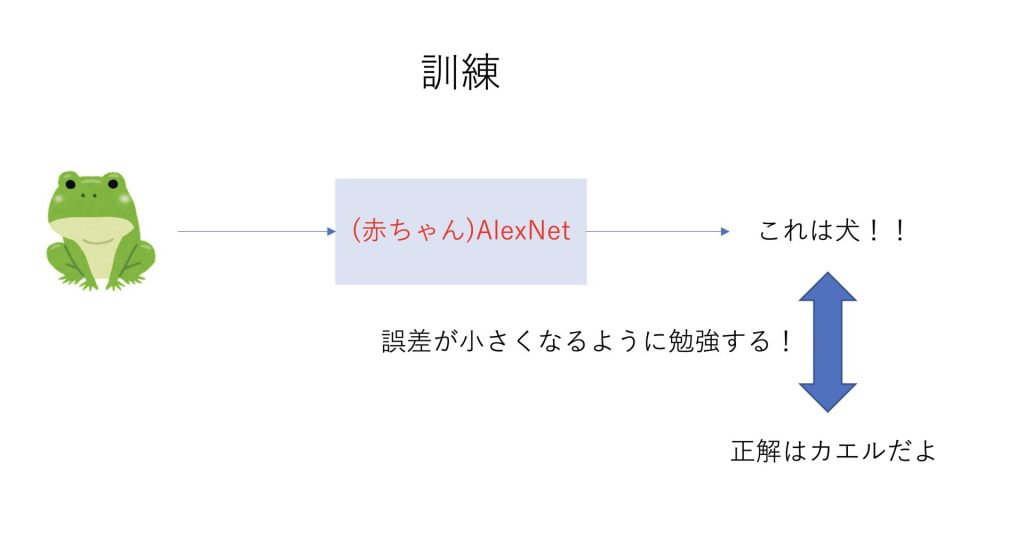
訓練の段階では、AlexNetは何も知らない赤ちゃんです。
何も知らないので、カエルの画像をみても、当てずっぽうで答えを言います。
その後答えを教えられることで、どんどん勉強して賢くなっていきます。
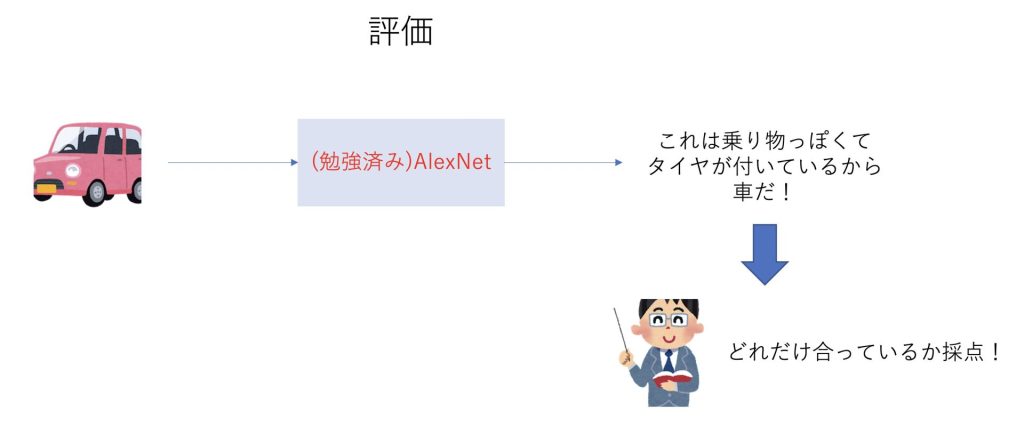
十分に勉強して賢くなったら次は評価の段階に入ります。
評価の段階では、正解は教えられません。
これまでに勉強した内容がしっかりできているかテストされます。
もちろん同じ自動車でも、訓練データとは異なる自動車の画像が与えられるので、うまく自動車の特徴を分析することができているのかということが求められます。
それでは実際にプログラムでやっていきましょう。
ライブラリのインポート
今回はPyTorchを使ってAlexNetを作っていきます。
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision.transforms as transforms
import numpy as np
from matplotlib import pyplot as plt
%matplotlib inlineデータセットのダウンロード
CIFAR-10はtorchvisionからダウンロードすることができるので、訓練データとテストデータに分けてダウンロードしていきます。
ダウンロードしたものを、dataloaderに格納することで使いやすくしています。
train_dataset = torchvision.datasets.CIFAR10(root='./data/',train=True,transform=transforms.ToTensor(),download=True)
test_dataset = torchvision.datasets.CIFAR10(root='./data/',train=False,transform=transforms.ToTensor(),download=True)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,batch_size=64,shuffle=True,num_workers=2)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,batch_size=64,shuffle=False,num_workers=2)AlexNetを定義する
次にAlexNetを定義していきます。
class AlexNet(nn.Module):
def __init__(self,num_classes=10):
super(AlexNet,self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3,64,kernel_size=11,stride=4,padding=5),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(64,192,kernel_size=5,padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(192,384,kernel_size=3,padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384,256,kernel_size=3,padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256,256,kernel_size=3,padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2,stride=2),
)
self.classifier = nn.Linear(256,num_classes)
def forward(self,x):
x = self.features(x)
# xを一次元化する
x = x.view(x.size(0),-1)
x = self.classifier(x)
return x
device = 'cuda' if torch.cuda.is_available() else 'cpu'
net = AlexNet().to(device)nn.Conv2dでは畳み込み演算、nn.MaxPool2dではMAX-Poolingを行っています。
それぞれについて具体的に知りたい方は、以下の記事をどうぞ。


損失関数と最適化関数を定義する
今回は分類問題ですので、交差エントロピー誤差を用いていきます。
#交差エントロピー誤差を使用
criterion = nn.CrossEntropyLoss()
#モーメンタム法を使用
optimizer = optim.SGD(net.parameters(),lr=0.01,momentum=0.9,weight_decay=5e-4)最適化関数にはたくさんあるので、色々試してみるといいかもしれません。

モデルの学習と評価
それではモデルを学習していきます。
実行には4分程度かかるかもしれません。
# 繰り返し回数
num_epochs = 20
train_loss_list = []
train_acc_list = []
val_loss_list = []
val_acc_list = []
for epoch in range(num_epochs):
# 値の初期化
train_loss = 0
train_acc = 0
val_loss = 0
val_acc = 0
# ここから訓練
net.train()
for i,(images,labels) in enumerate(train_loader):
images,labels = images.to(device),labels.to(device)
# 勾配を0にする
optimizer.zero_grad()
# 順伝播の計算
outputs = net(images)
# 誤差の計算
loss = criterion(outputs,labels)
# 訓練誤差
train_loss += loss.item()
# 予測結果と正解ラベルが同じ数(同じ場合に1となる)
train_acc += (outputs.max(1)[1]==labels).sum().item()
# 誤差の逆伝播
loss.backward()
# 重みの更新
optimizer.step()
# 訓練誤差の平均
avg_train_loss = train_loss / len(train_loader.dataset)
# 正解率(訓練)の平均
avg_train_acc = train_acc / len(train_loader.dataset)
# ここから評価(dropoutやバッチ正規化を定義した場合に必要)
net.eval()
# 学習モデルを固定
with torch.no_grad():
for i,(images,labels) in enumerate(test_loader):
images,labels = images.to(device),labels.to(device)
# 順伝播の計算
outputs = net(images)
# 誤差の計算
loss = criterion(outputs,labels)
# 評価誤差
val_loss += loss.item()
# 正解率(評価)
val_acc += (outputs.max(1)[1]==labels).sum().item()
# 評価誤差の平均
avg_val_loss = val_loss / len(test_loader.dataset)
# 正解率(評価)の平均
avg_val_acc = val_acc / len(test_loader.dataset)
# プロット用リストへの格納
train_loss_list.append(avg_train_loss)
train_acc_list.append(avg_train_acc)
val_loss_list.append(avg_val_loss)
val_acc_list.append(avg_val_acc)それでは出来上がったモデルの結果をプロットしていきます。
結果のプロット
まずは誤差をプロットしていきます。
plt.figure()
plt.plot(range(num_epochs),train_loss_list,label='train_loss')
plt.plot(range(num_epochs),val_loss_list,label='val_loss')
plt.legend()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.title('Training and Validation loss')
plt.grid()縦軸が誤差の値で、横軸が繰り返し数です。
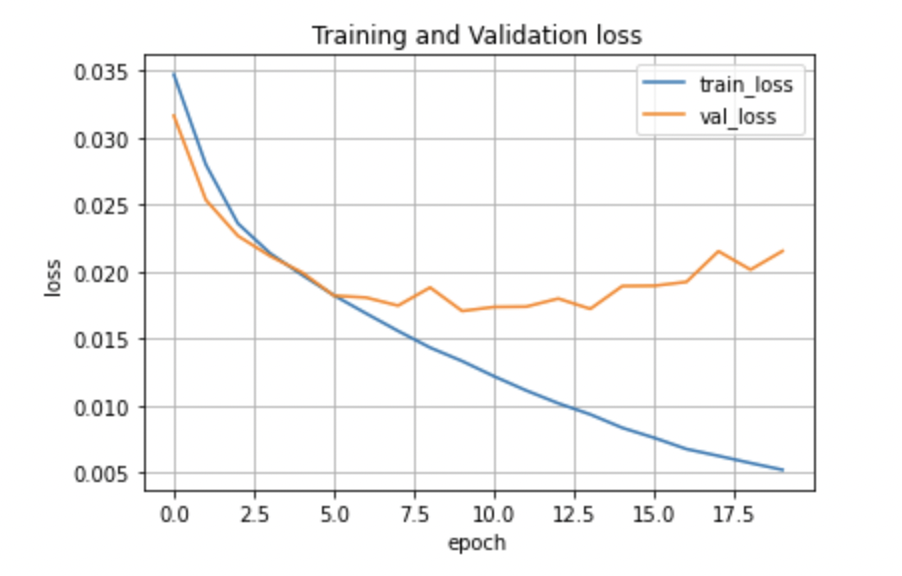
訓練データの誤差が0に近づいていっているのに対して、評価誤差は横ばい、あるいは少しずつ大きくなっていそうな感じです。
評価誤差の最小の誤差は0.017程度になりました。
次に正解率をプロットしてみます。
plt.figure()
plt.plot(range(num_epochs),train_acc_list,label='train_acc')
plt.plot(range(num_epochs),val_acc_list,label='val_acc')
plt.legend()
plt.xlabel('epoch')
plt.ylabel('acc')
plt.title('Training and Validation accuracy')
plt.grid()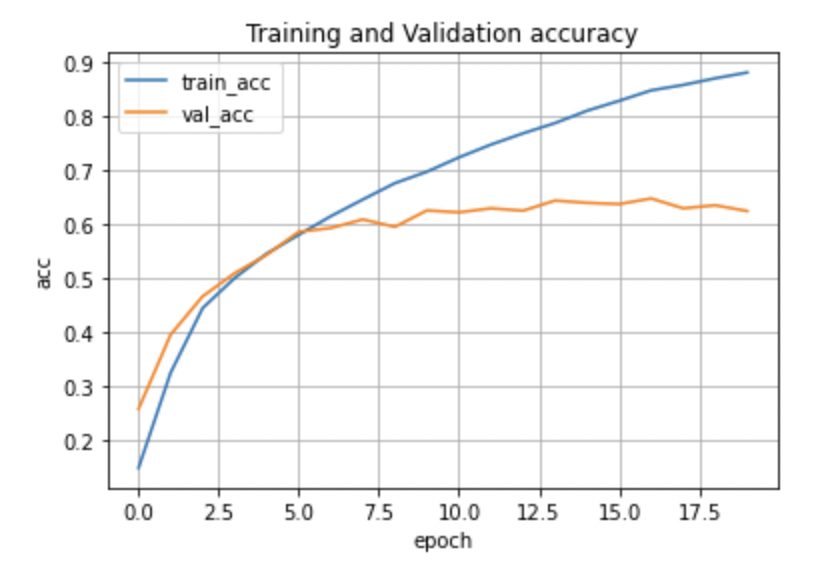
正解率も訓練データは高くなり続けているのに対し、評価データの正解率は63%あたりで横ばいになっています。
前回のニューラルネットワークより正解率が上昇した理由としては、ニューラルネットワークは画像を入力する際に一次元化しないといけないので、画像の情報が損なわれてしまうことが考えられます。
やはり画像分類には畳み込みニューラルネットワークが合っているようですね。
最後まで読んでいただきありがとうございました。
他にもいろんな記事があるにゃ。



コメント