
はじめに

どーも、学生エンジニアのゆうき(@engineerblog_Yu)です。
プログラミング初心者だけど株価予測をしてみたいなんて思っている方はいませんか?
今回はProphetというPythonライブラリを用いて世界一簡単に株価予測をやってみました。
今回の記事を特に読んで欲しい方は
- 株式投資に興味がある人
- 機械学習に興味がある人
- データサイエンスに興味がある人
となっています。
かぶってなににゃ?
コードを見るのがめんどくさいという方は、なんとなくプログラミングでこういう株価予測ができるということだけでも知っていただけたらなと思います。
完成物
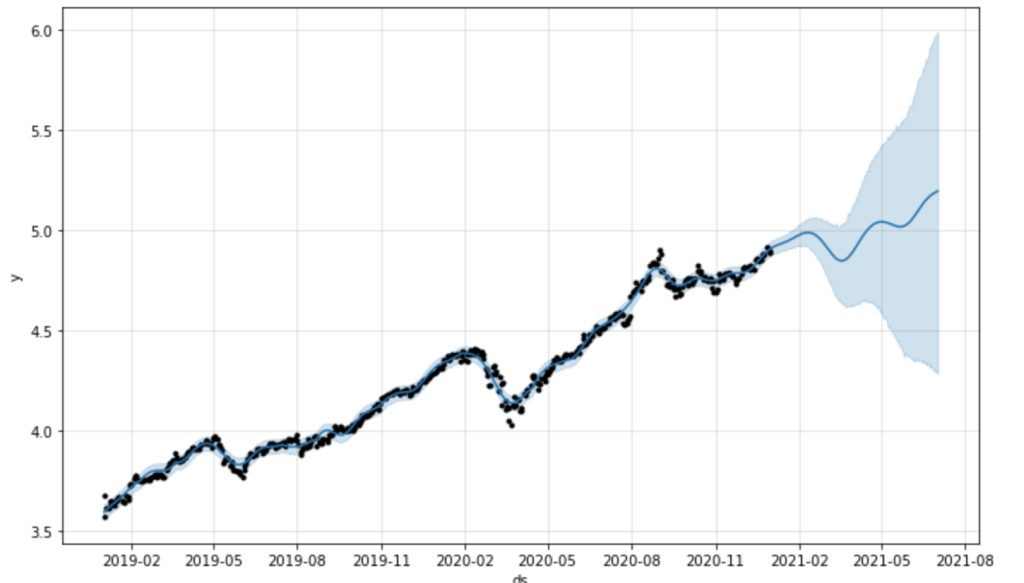
今回はこちらのような株価予測をしていこうと思います。
黒い点が実際の値で青い線が予測される値です。
今回用いるのはアップル社の株価のデータで、csv形式で2019年から2021年までの2年間のデータを持ってきました。
動作環境はJypyter Notebookです。
csvはアップルの公式サイトからダウンロードできるのでやってみたい方はこちらからどうぞ。
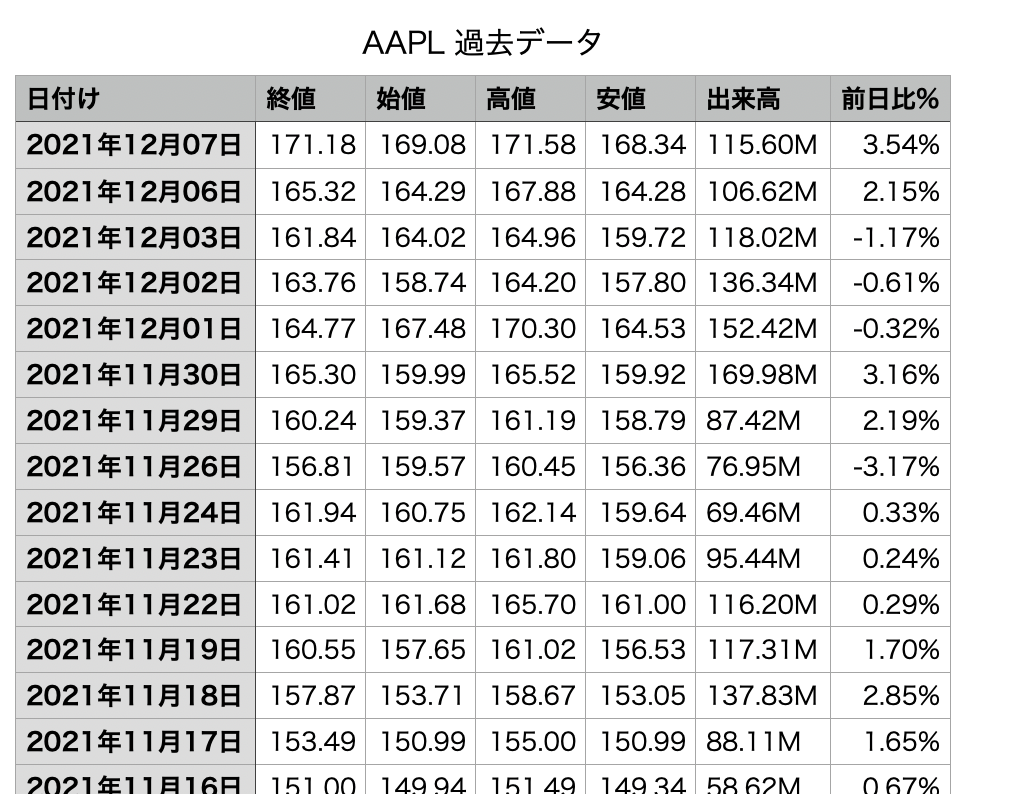
csvはこんな感じです。
それではやっていきましょう。
一応予備知識としてこちらもどうぞ。

まずは必要なライブラリをインポートしていきます。
日付の欄が日本語が入っていたり時系列が逆になっていたりと見づらいので前処理をしていきます。
import math
import numpy as np
import pandas as pd
from prophet import Prophet
import matplotlib.pyplot as plt
# csvファイルの読み込み
df = pd.read_csv('AAPL 過去データ.csv')
# データの前処理
df = df.iloc[::-1]
df.index = range(len(df))
# 日付の整形
for i in df:
df['日付け'] = pd.to_datetime(df['日付け'], format='%Y年%m月%d日')それではまずはこちらのコードでグラフを表示してみます。
plt.figure(figsize=(18, 10))
plt.xticks([0,100,200,300,400,500],[df['日付け'][0],df['日付け'][100],df['日付け'][200],df['日付け'][300],df['日付け'][400],df['日付け'][500]])
plt.plot(df.iloc[:,1:2],label='end price')
plt.plot(df.iloc[:,2:3],label='start price')
plt.plot(df.iloc[:,3:4],label='high price')
plt.plot(df.iloc[:,4:5],label='low price')
plt.xlabel('year')
plt.ylabel('stock price')
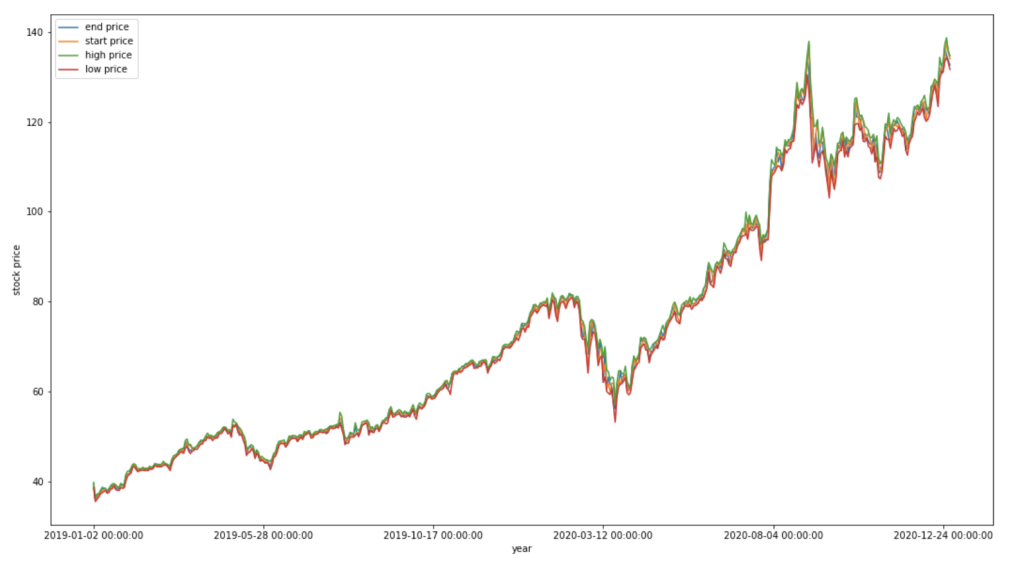
plt.legend(loc='best')こちらが2019年から2021年までの実際のアップル社の株価変動です。
それではProphetを使う準備をしていきましょう。
Prophetsとは?
それではまずは株価予測を理解するためには不可欠なProphetsとはどのようなモデルなのかについて説明していこうと思います。(難しいと思った方は飛ばしていただいても結構です。)
(私の研究の方から抜粋してきているので語調が変わりますが気にしないでください。)

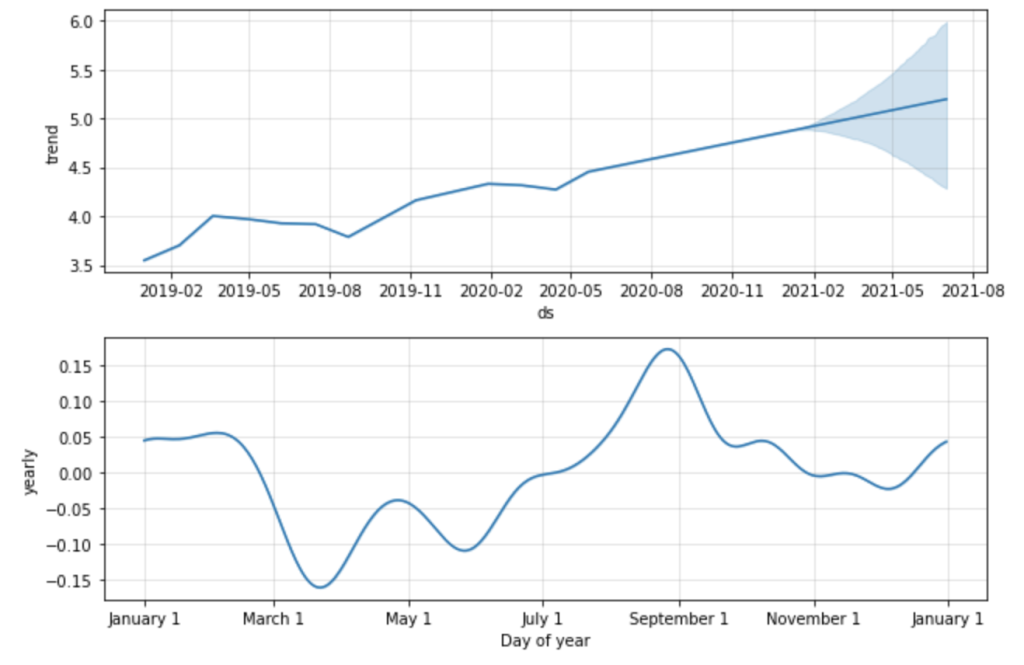
後の結果を先に載せますが一つ目のグラフがg(t)の項で二つ目のグラフがs(t)の項です。
この二つのグラフを足し合わせることで株価を予測します。
次に各項をどのような数式で表しているかについての記述です。

難しそうに書いてありますがg(t)で折れ線を表していてs(t)で周期的な波を表しているという認識で大丈夫かと思います。
それではProphetを使って実際に株価予測をしていきましょう。
実際に株価予測をしてみる
Prophetでは日付のデータを「ds」,予測するデータを「y」としなければならない決まりがあります。
まずはその形式に変えてあげましょう。(今回はend priceのみを予測していきます。)
# Prophetを用いるためのデータの整形
data_train = df.iloc[:,0:2]
data_train.columns = ['ds','y']
#yの値が大きいサンプルの誤差を小さくするために対数変換する
data_train['y'] = np.log(data_train['y'])
こちらはProphetオブジェクトの作成です。
傾向変化点の数を指定することでトレンドの折れ線が何回曲がるかを決めることができます。
また年、週、日単位で変動を考慮するか指定します。
今回は年だけを考慮してやっていこうと思います。
model = Prophet(
growth='linear', # 傾向変動の関数.非線形は'logistic'
yearly_seasonality = True, # 年次の季節変動を考慮有無
weekly_seasonality = False, # 週次の季節変動を考慮有無
daily_seasonality = False, # 日次の季節変動を考慮有無
changepoint_range = 0.80, # 傾向変化点の候補の幅で先頭からの割合。
n_changepoints = 15, # 傾向変化点の数
holidays = None,#休日のデータはないのでNone
)
model.fit(data_train)それでは予測した結果をプロットしていきましょう。
periodsに183を引数として渡すことでこれから半年間の株価予測をしていきます。
future = model.make_future_dataframe(periods=183, freq='M')
pred = model.predict(future)
pred = model.plot(pred)冒頭にあるグラフが表示されました。
黒くプロットされているのは実際の訓練用データです。(end price)
そして青く表示されているのが予測される値で80パーセントの確率で信頼できる範囲が青く表示されています。
またこちらのコードで中身を表示することができます。
fig_components = model.plot_components(pred)一つ目のグラフがトレンド項で二つ目のグラフが年の周期関数の項です。
たったこれだけのコードで予測分析ができるProphetに感謝ですね。
モデルの評価
それでは実際の2021年1月から2021年7月までのデータをプロットすることでモデルを評価していきましょう。
プロットした結果はこのようになりました。
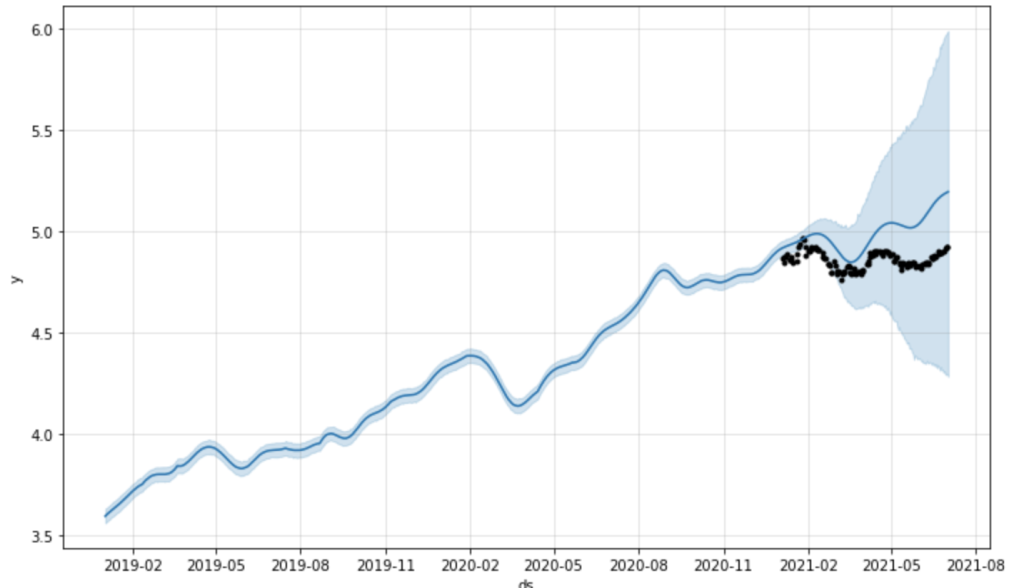
黒い点が実際のデータです。
実際の予測値とは少し下回っているが(コロナ?)ほとんどのデータが80%信頼区間の中に入っていて、かつ大まかな経済の波は予測できているように見えます。
また誤差を測る指標である平均絶対値誤差(MAE)、平均二乗誤差(MSE)、平均二乗偏差(RMSE)に関してはこのようになりました。

平均で誤差18ドルの範囲で予想できていることがわかります。
ほかにもいろんな記事があるにゃ。
データサイエンスの記事

データサイエンスを勉強したい方に
最後にデータサイエンスを勉強したい方向けにおすすめの講座を紹介します。
Udemyのこちらのコースです。
こちらのコースではデータサイエンスを0から目指す方向けに
- ビジネススキル
- 大学基礎数学
- プログラミングスキル
の三つの全てをまとめてくれています。
とてもわかりやすく特にデータサイエンスに馴染みのない方はこの講座から始めてみるのが良いかと思います。
かなり量が多いコースですので自分が足りないと思う部分、興味がある分野だけでも大丈夫です。
このコースは通常かなり値段が高いのでセール中に買うのが良いと思います。
※Udemyでは月に1回程度90%OFFセールがあります。
おわりに

今回はProphetを用いた株価予測を解説していきました。
今回はアップル社の株価でしたが他の会社でも株価のデータでなくても何にでも応用することができると思います。
理解するのは少し大変かもしれませんが動かしてみることは簡単にできると思います。
実用的で楽しいプログラミングができるきっかけになれば幸いです。


コメント