
初めに
こんにちは!シミュレーション技法研究室に所属しているゆうき(@engieerblog_Yu)です。
今回は研究でGANを用いる機会があったので、誰でもわかるように解説していきたいと思います!
シミュレーションや私の研究についての記事も併せてどうぞ。

GANとは?
今回は敵対的生成モデルと呼ばれる、GAN(Generative adversarial network)(通称ガン,ギャン)についてまとめていきたいと思います!
GANは二つのモデルから構成されています。
生成器・・・データを生成するモデル
識別器・・・データが本物か偽物かを判別するモデル
GANが敵対的と呼ばれるその所以は、生成期と識別器を競わせて学習を進ませていくという背景があります。
よくわからないと思うので具体的に説明していきたいと思います!
GANの学習の流れ
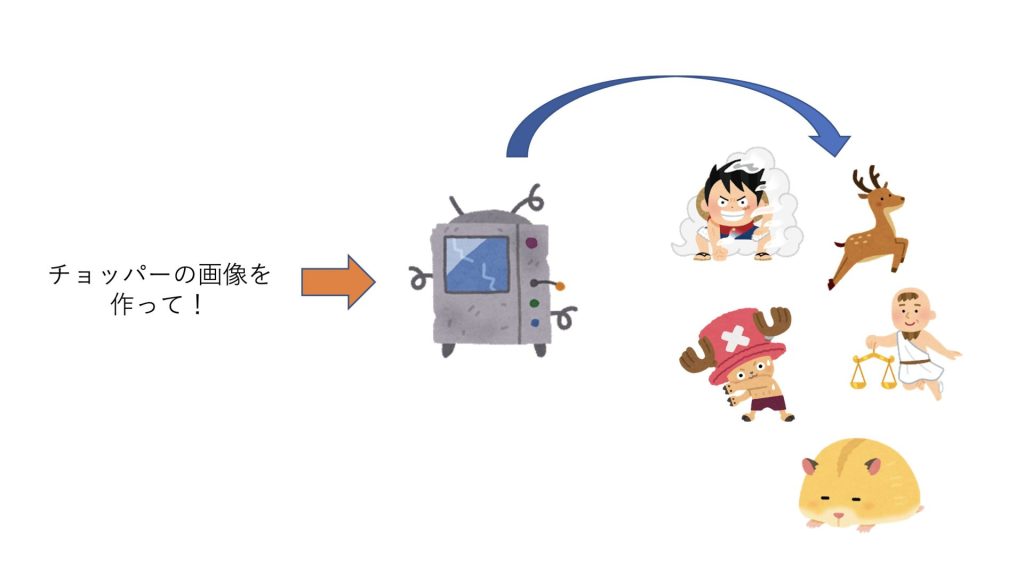
今回はチョッパーと入力すると、チョッパーの画像を作ってくれるような生成モデルを作成したいとします。
学習が十分でない生成器は、オンボロのコンピュータのようになります。
以下のように、チョッパーの画像とは程遠い画像ばかりを出力します。
識別器は、データが本物か偽物かを判別するモデルです。
生成器と同様に、学習が十分でない識別器は本物か偽物かを判別することができません。

識別器は間違えることを繰り返して、どんどん正解率を上げていきます。

識別器は学習を通して、わずかな誤りも見つけられるようになっていきます。
識別器の学習と同時並行で、生成器の学習も行われています。
生成器は、識別器が間違えるように学習を行います。
本物のチョッパーか偽物のチョッパーか、わからないレベルの画像を作れるようになります。
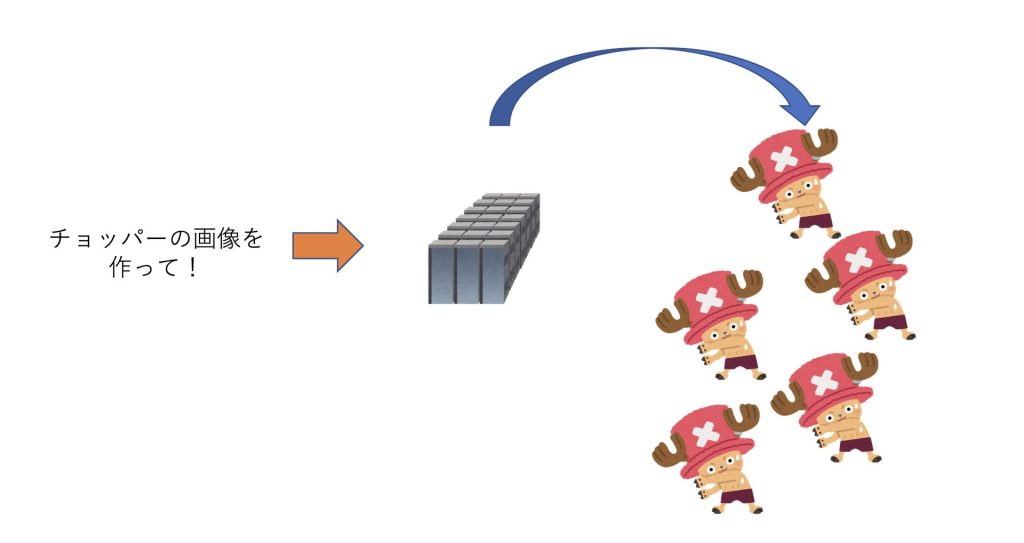
ここまで来たらもう、本物か偽物か判別できないチョッパーの画像を生成できるモデルが出来上がっている訳です。
モデルの全体像
これまでの話を一般化して、モデルの全体像についてまとめたいと思います。
生成器は入力を元にデータを生成して出力します。
この出力は画像だったり音声だったり動画だったりします。
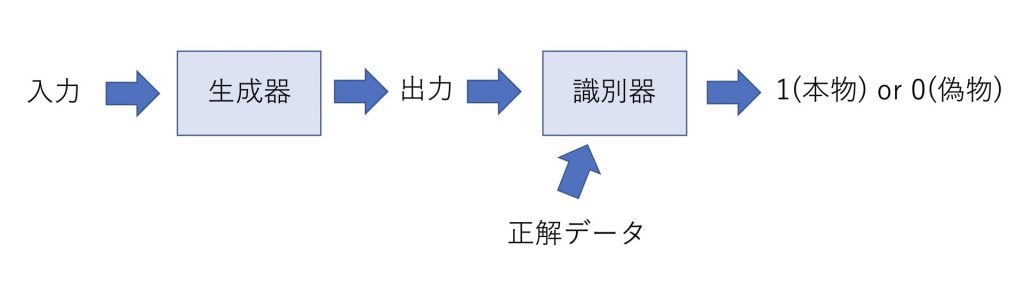
識別器は生成器が生成したデータと正解データを比較して、どっちが本物でどっちが偽物かを当てます。
この際に識別器が間違えた場合、誤差が逆伝播し、モデルの学習が行われていきます。
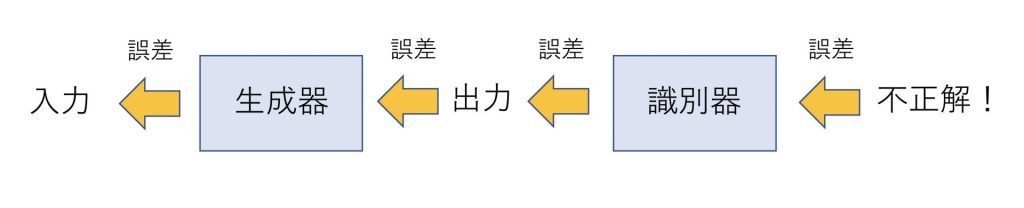
生成器が識別器を騙すような精度の高い出力を出すのに対して、識別器はわずかな誤りも見つけられるように学習していきます。
そのように生成器と識別器が競い合って学習していくことで、GANは精度の高い生成モデルを実現っすることができます。
GAN以外の生成モデル
他にもVAE(変分自己符号化器)といった生成モデルもあります。
生成モデルについてより詳しく知りたい方は、こちらも併せてどうぞ。

まとめ
GANには生成器と識別器の二つのモデルを使った生成モデル
生成器はデータを生成するモデルで、識別器はデータが本物か偽物か判別するモデル
生成器と識別器を競わせていくことでモデルを学習していく
今回は生成モデルの一つであるGANについてまとめました!
ディープラーニングを面白いと思っていただけたら幸いです。
ディープラーニングを、より深く知りたい方むけのおすすめ書籍です。
最後まで読んでいただきありがとうございました。
他にもいろんな記事があるにゃ。

コメント