初めに
こんにちは。可視化研究室でサロゲートモデルを研究している、情報系大学生のゆうき(@engieerblog_Yu)です。
今回はサロゲートモデルの中でも画像ベースのモデルである、InSituNetについてまとめていきたいと思います。
今回は、以下の論文を日本語で分かりやすくまとめた内容になっています。
InSituNet: Deep Image Synthesis for Parameter Space Exploration of Ensemble Simulations
概要
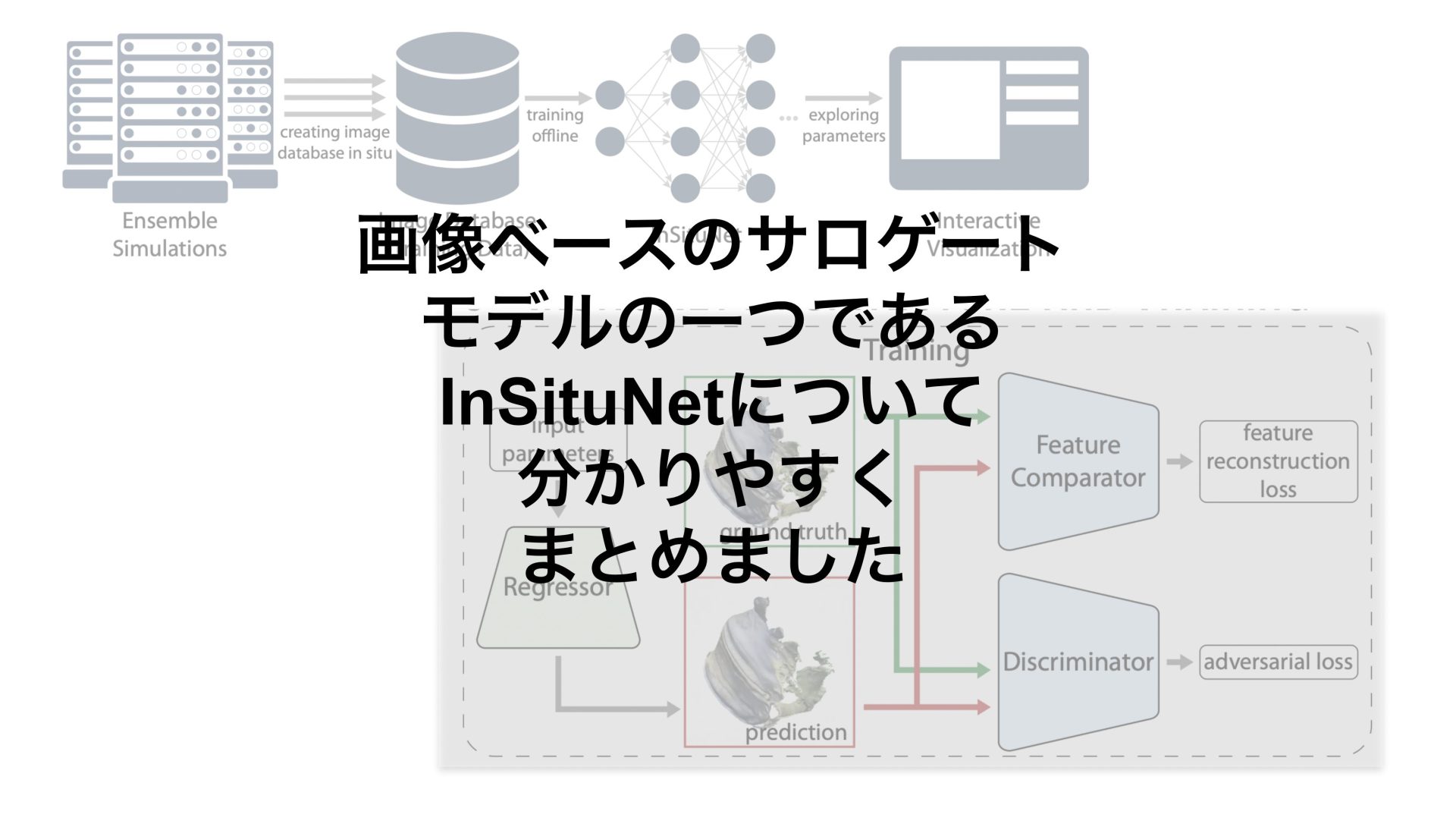
概要は以下になります。
訓練データ(InSitu可視化画像)の収集
InSituNetの学習
学習モデルを使った推論
まずはInSituNetの利点についてまとめていきます。
InSituNetを使うと何が良いのか?
InSituNetを含めたサロゲートモデルを用いると、以下のことが達成できます。
シミュレーションの初期パラメータ探索を効率化できる
シミュレーションの実行が大規模になると、一回の実行に何時間もかかるものもあります。
そのようなシミュレーションモデルをサロゲートモデルで代替することによって、シミュレーション実行時間を数秒に短縮します。
シミュレーションの初期パラメータには、正解の値があります。
しかし正解の値というのは、大体の目星をつけることは可能ですが、シミュレーションをしないと具体的な値は分かりません。
もし100時間かかるシミュレーションで、1%の確率で正解の初期パラメータを見つけられるとすると平均100×100時間かかることになります。
そのためシミュレーション実行時間を削減できるサロゲートモデルが使われています。
サロゲートモデルについては以下の記事でより詳しく解説しています。

サロゲートモデルには、シミュレーションの出力を使って学習するものと画像を使って学習するものがあります。
InSituNetは画像を使って学習を行うので、画像ベースのサロゲートモデルと言われています。
訓練データ収集
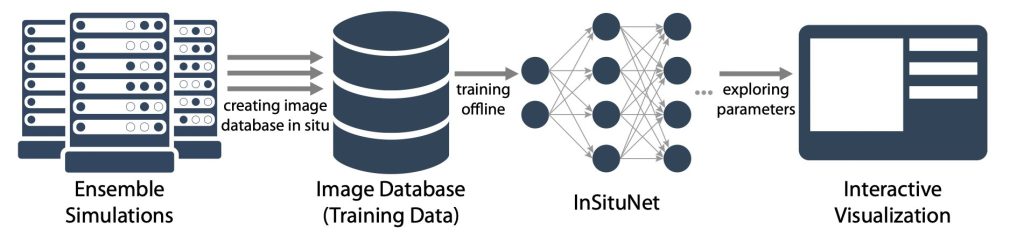
InSituNetというモデルを学習するためには、四つのものが必要です。
シミュレーションパラメータ
可視化パラメータ(等値面など)
視点パラメータ
可視化画像
上記の四つを集めるためにInSitu可視化を行います。
InSitu可視化とは、シミュレーション出力をコンピュータ上に保存することなくそのまま可視化を行うという手法です。
これにより計算資源を節約することができます。
イメージとしては、シミュレーションパラメータと可視化パラメータと視点パラメータを設定すると、一つの画像が出力されるというようなイメージです。
上記のように集めた、四つのデータのセットを基にInSituNetを学習していきます。
モデルの訓練
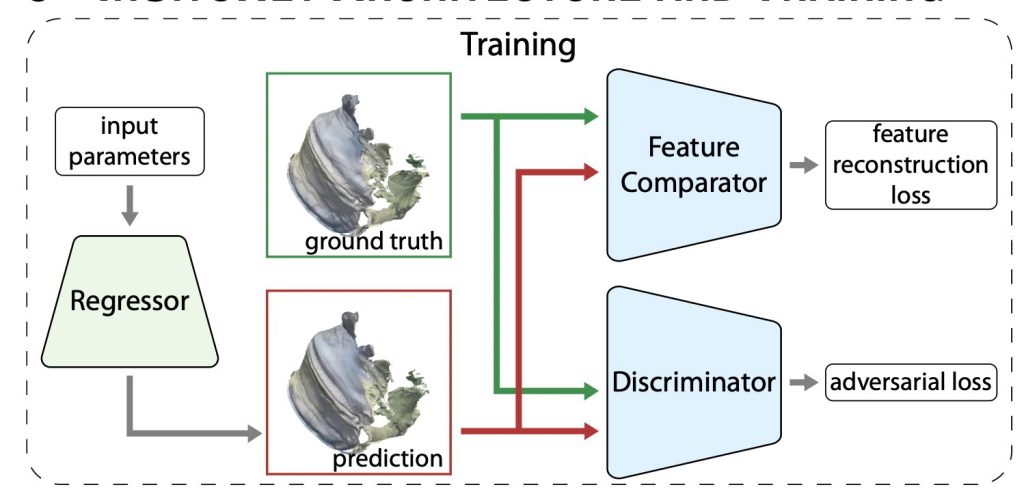
InSituNetには、三つのニューラルネットワークが用いられています。
Regressor → GANベースの生成モデルで、入力パラメータに対して予測画像を生成する
Feature Comparator → 正解画像(ground truth)と予測画像(prediction)の辺や形などの特徴の誤差を出力
Discriminator → 正解画像(ground truth)と予測画像(prediction)の分布の差を誤差として出力
Feature ComparatorとDiscriminatorによって出力される誤差が小さくなるように三つのモデルを学習していきます。
GANについてあまり理解していない方は、以下の記事も併せてどうぞ。

推論
十分に学習を行ったモデルを用いて推論を行います。
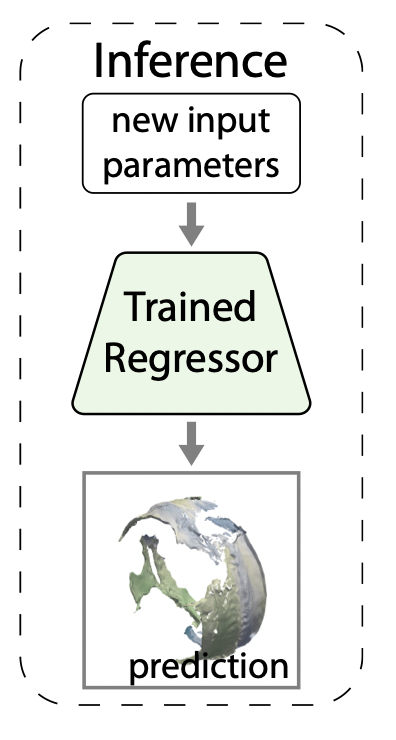
学習済みモデルを用いて、シミュレーションパラメータと可視化パラメータ、視点パラメータを入力すると予測された可視化画像を作成することができます。
結果の一部
結果の一部です。
以下はダークマターの対数密度を出力とするシミュレーションに、InSituNetを適用したデータです。
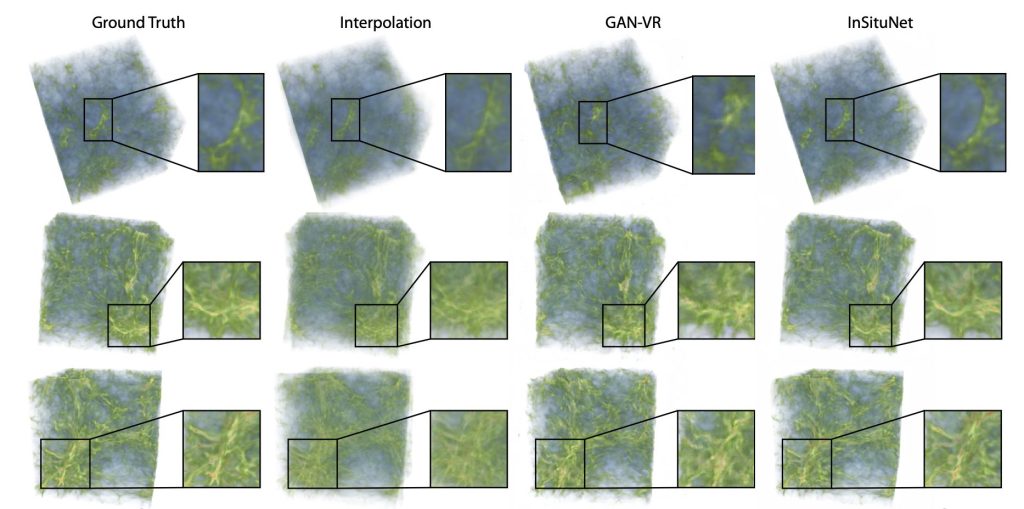
著者の方が実験した三つの手法の中では、最もGround Truthに近い画像が出力できているように思えます。
実験や手法について、より詳しく知りたい方は以下のリンクから元論文を参照できます。
InSituNet: Deep Image Synthesis for Parameter Space Exploration of Ensemble Simulations
終わりに
今回はInSituNetについてまとめました。
かなり良さそうに見えるInSituNetですが、著者は以下のような問題点も挙げています。
可視化パラメータが固定されている
精度と解像度がまだまだ足りない
視点が固定されているデータ、InSitu可視化されているデータへの適用などにはとても良いなと個人的には思いました。
著者の方は他にもVDL-Surrogateなどを提案していて、そちらについても簡単にまとめました。
最後まで読んでいただきありがとうございました。



コメント