
初めに
こんにちは。将棋と筋トレが好きな、情報系大学生のゆうき(@engieerblog_Yu)です。
今回は、過学習を避けるために一般的に用いられている、leave-p-out Cross Validation(P個抜き交差検証)についてまとめていきます。
類似している手法としてk分割交差検証というものもあります。

交差検証とは?
交差検証では、訓練データを変えたモデルを何個も作り、それらを平均化したモデルを作成します。
交差検証の目的は、過学習を避けるためです。
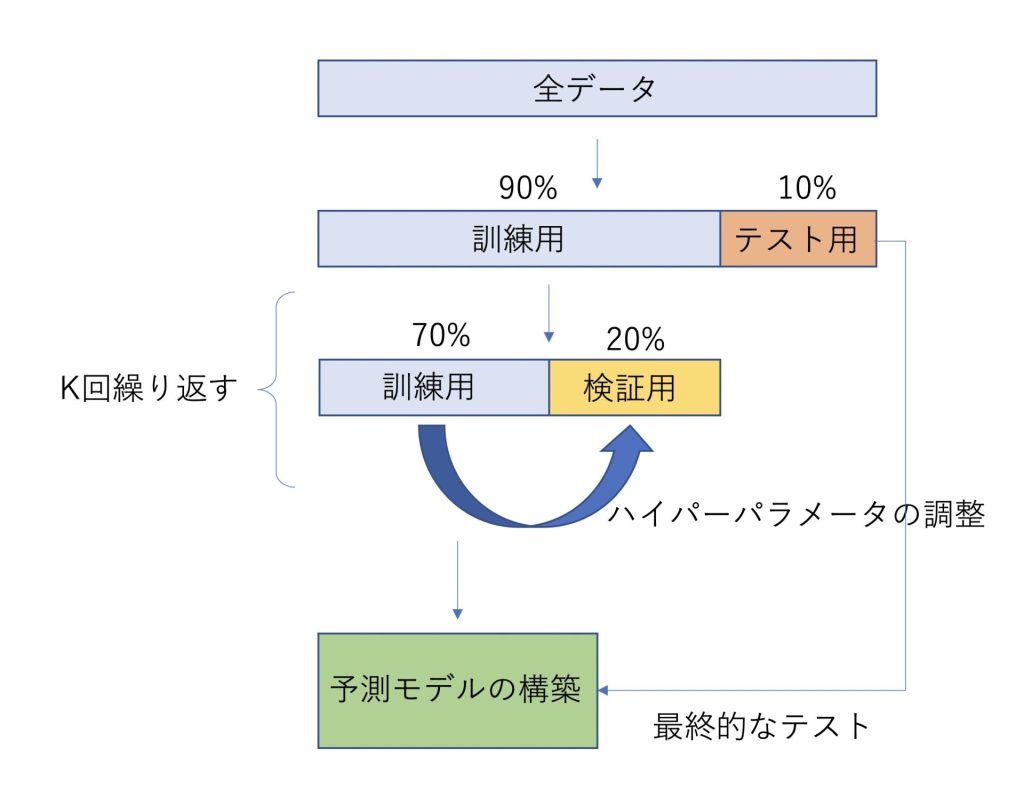
交差検証の概観は以下のようになります。
①全データの中から、テスト用データを10%ランダムに抽出する
②全データの70%と20%を訓練用データと検証用データに分ける
③モデルを学習させる
④抽出するデータを変えてk回②,③を行う
⑤k個のモデルを平均化して予測モデルを構築する
⑥予測モデルの性能をテストデータで確認する
ざっくりまとめると以下のような図になります。
④と⑤について、よく分かりにくいと思うのでより具体的に解説していきます。
交差検証は過学習を避けるために用いられる
異なる訓練データの組をk回抽出→モデルをk個作成する
テスト用のデータをランダムに抽出して、残ったデータから訓練データをk回抽出します。
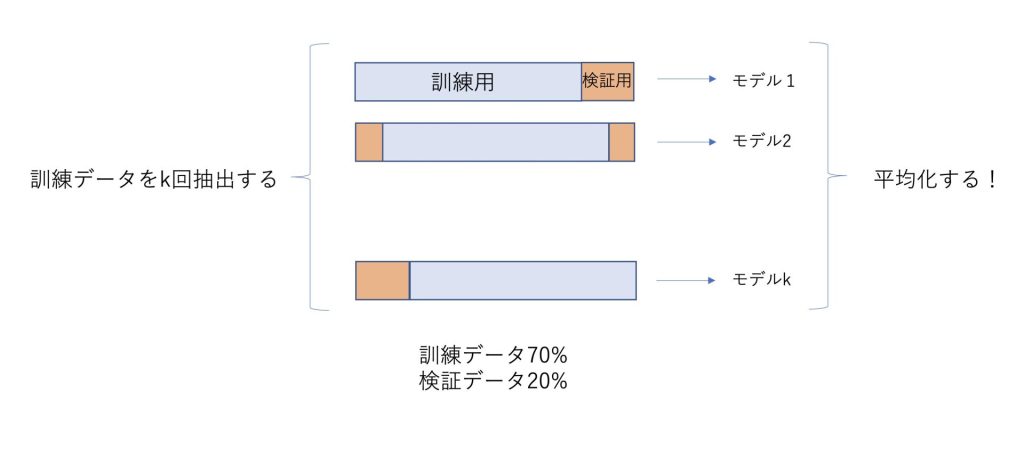
それぞれランダムに抽出された訓練用データに対して、モデルをk個作成します。
P個ぬき交差検証と呼ばれているのは、この段階で検証用のデータをP個抜き出していることが由来です。
検証用のデータは、回帰アルゴリズムを用いる際の、ハイパーパラメータの調整に使われます。

それらのk個の学習済みモデルを平均化したものを予測モデルとします。
leave-p-out Cross Validationを図で表したもの
leave p-out Cross Validationを図で表したものは以下のようになります。
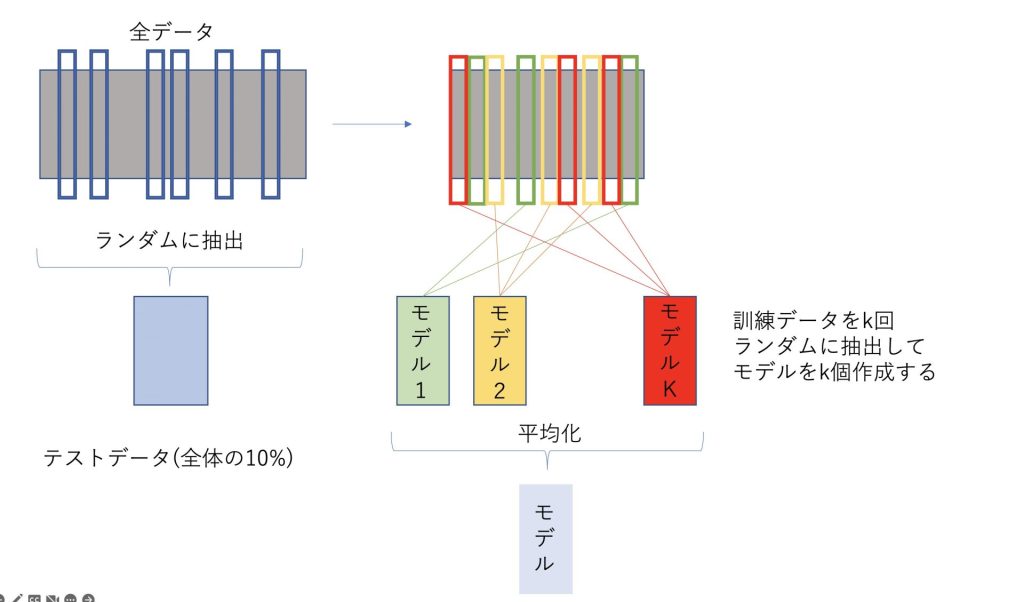
全データからテストデータを抽出して、残ったデータからk個のモデルを作成し、それらを平均化したものをモデルとします。
適切に繰り返しの回数kを大きくすると、モデルの精度は良くなる傾向があります。
補足
データセットが大きい場合、テスト用データと検証用データを少なくして、訓練用データを70%より大きくするというようなこともあるようです。
まとめ
K分割交差検証は過学習を避けるために用いられ、以下の流れで実装される
①全データの中から、テスト用データを10%ランダムに抽出する
②全データの70%と20%を訓練用データと検証用データに分ける
③モデルを学習させる
④抽出するデータを変えてk回②,③を行う
⑤k個のモデルを平均化して予測モデルを構築する
⑥予測モデルの性能をテストデータで確認する
今回は、過学習対策に用いられるleave-p-out Cross Validationについてまとめました。
機械学習、ディープラーニングを学びたい方におすすめの入門書籍です。
ディープラーニングの理論が分かりやすくまとめられていて、力を身につけたい方におすすめです。
最後まで読んでいただきありがとうございました。
他にもいろんな投稿があるにゃ。





コメント