こんにちは!
シミュレーション技法研究室で、サロゲートモデルの研究をしているゆうき(@engieerblog_Yu)です。
今回は、CoordNetという座標ベースのサロゲートモデルについて論文をまとめていきたいと思います。
元論文はこちらです。
目次
概観
論文の概観は以下になります。
シミュレーションのデータ生成・可視化画像生成どちらにも対応するようなCoordNetを提案
CoordNetは、NNベースのモデルを使うことで、解像度を変更したり、さまざまなタスク(データ生成・可視化画像生成)に対応できる
背景
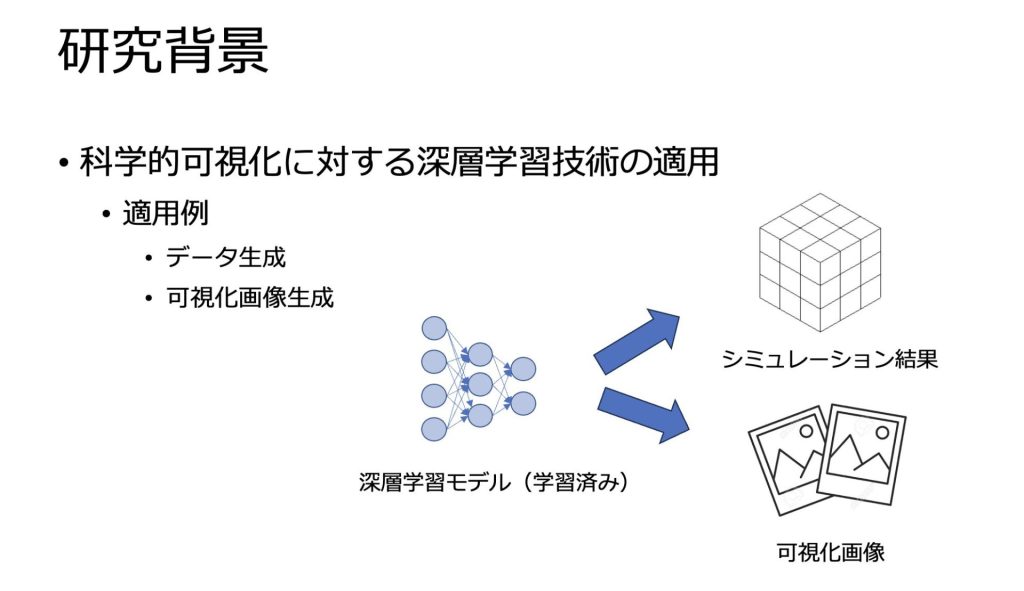
背景といたしまして、現在科学的可視化に対して、深層学習技術が用いられています。
科学的可視化に対する深層学習技術を使ったアプローチとしては、シミュレーション結果を学習するデータ生成、可視化画像を学習する可視化画像生成の二つがあります。
関連研究
関連研究として、データ生成に関連する研究と可視化画像生成に関連する研究が挙げられています。
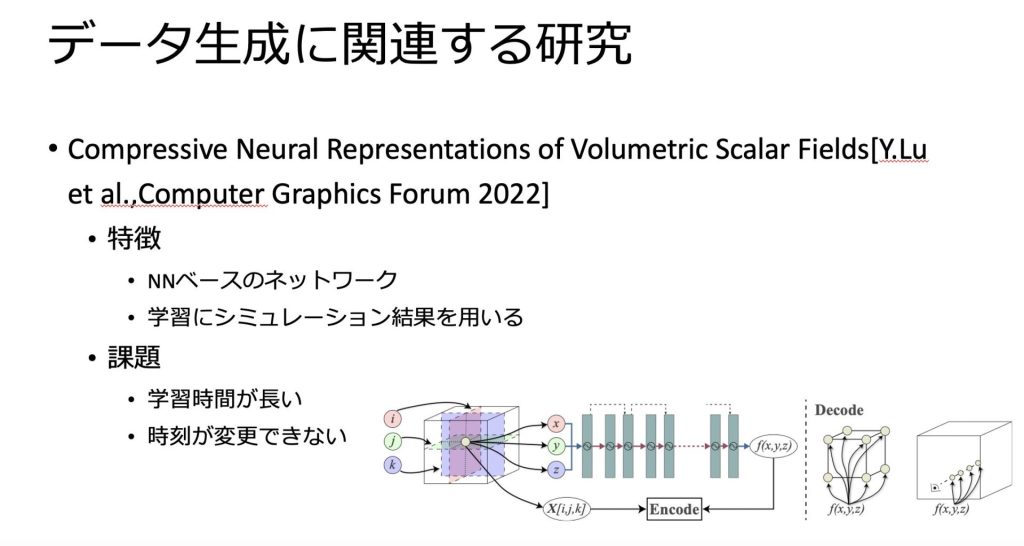

ただしこちらは、データ生成、可視化画像生成どちらかのタスクにしか対応できません。
目的
上記の背景から、以下のようなモチベーションが湧きます。
データ生成・可視化画像生成、どちらのタスクにも対応できるようなフレームワークを設計したい
しかし、それには多くの課題があります。
ボリュームデータと画像を含む多様なデータタイプを表現できるように定式化しなければならない
フレームワークの要件として、解像度を変更できるようにしたい
そのような課題を解決することが、CoordNetの目的です。

提案手法
提案手法についてです。
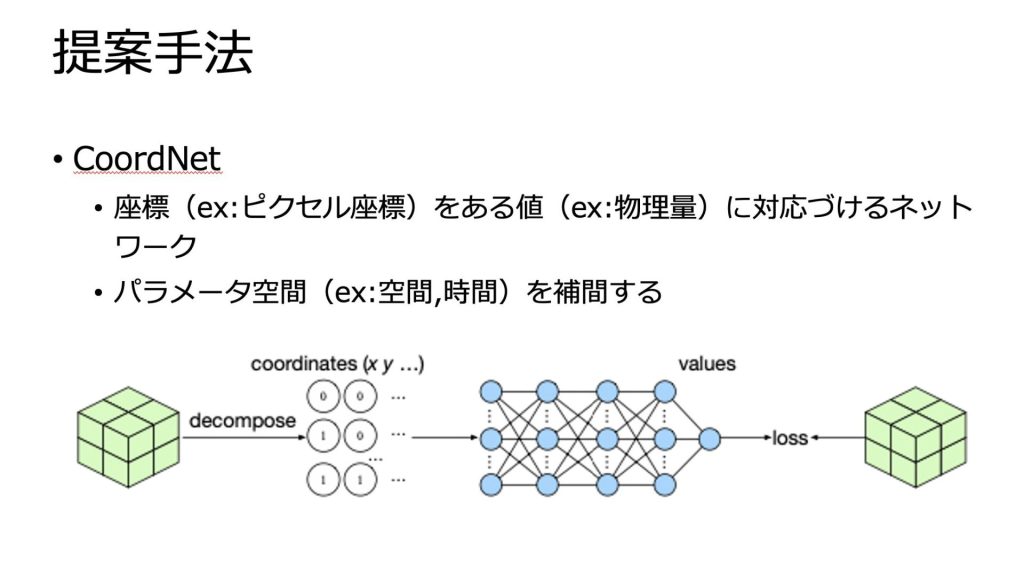
CoordNetは、INRというネットワークを用いていることで、フレームワークを構築しています。
INRを用いる理由を説明するために、CNNの問題からまとめていきます。
CNNの問題
CNNには、以下のような問題点があります。
CNNは高解像度のデータをうまく処理できない
CNNはグリッド状でのみの予測で、間を補完できない
アーキテクチャの設計がタスクに依存する
このようなCNNの問題点を解決するために、INRが用いられます。
INRとは?
INRは、信号のドメイン(すなわち座標)をその座標の値(例えば画像のRGBカラー)にマッピングする連続関数として信号をパラメータ化するようなモデルのことです。
CNNとは異なり、連続的な値を扱うことが特徴です。
今回のCoordNetは、INRをベースとしたモデルが使われています。
INRの利点
INRの利点は以下です。
任意の解像度のデータを処理できる
パラメータ空間を連続的に補間できる(空間的,時間的)
データ生成・可視化生成どちらにも対応
このような利点により、フレームワークを構築することが可能になります。
モデルのアーキテクチャ
モデルのアーキテクチャはEncoder-Decoderベースのネットワークです。
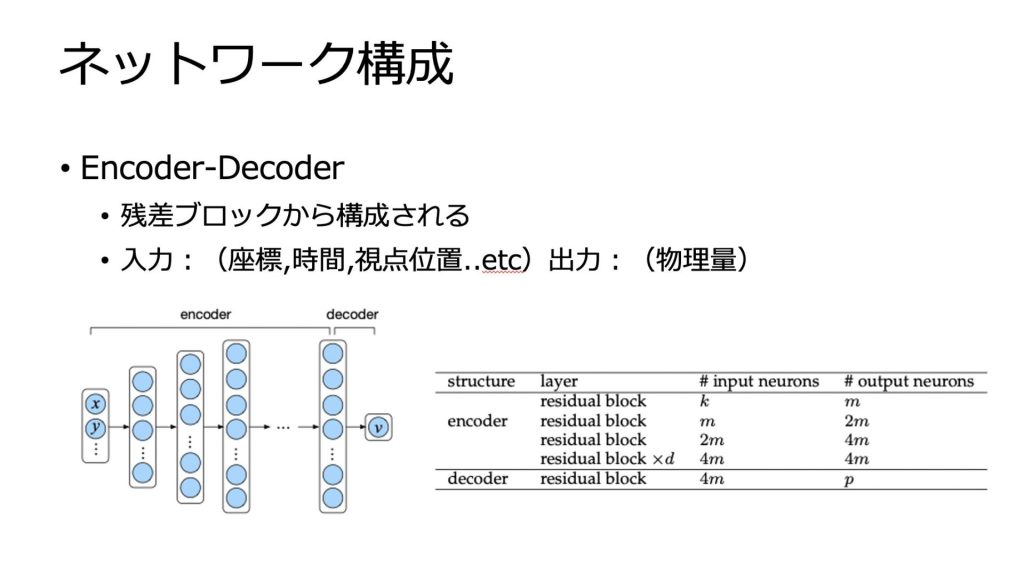
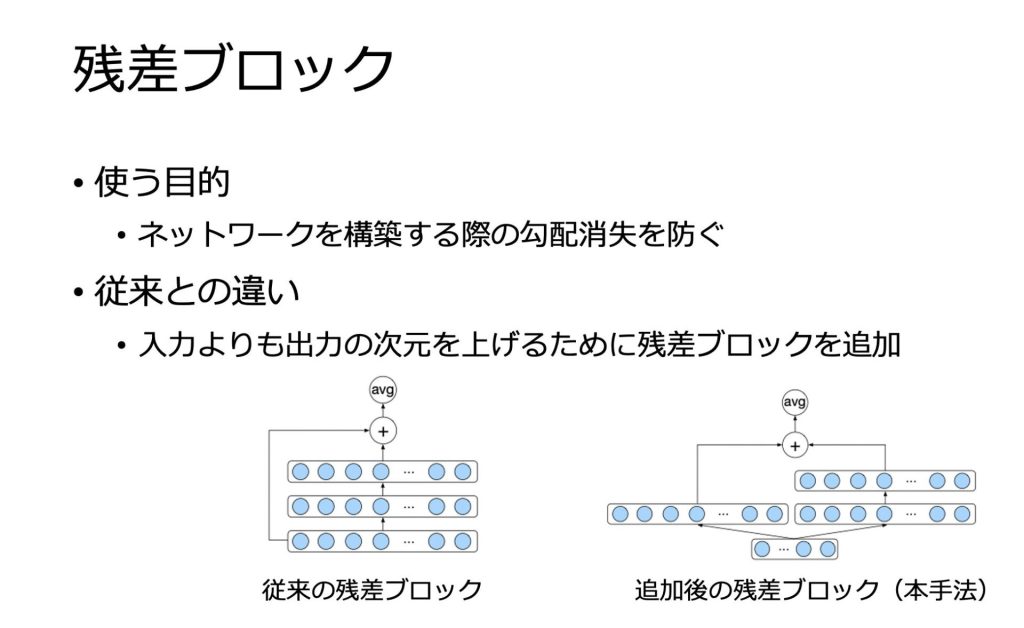
Encoder-Decoderの各層は残差ブロックから構成されます。
データ生成
データ生成に関しては、TSRとSSRの二つがまとめられていましたが、今回は時間に対する補間(TSR)に対してのみ紹介します。
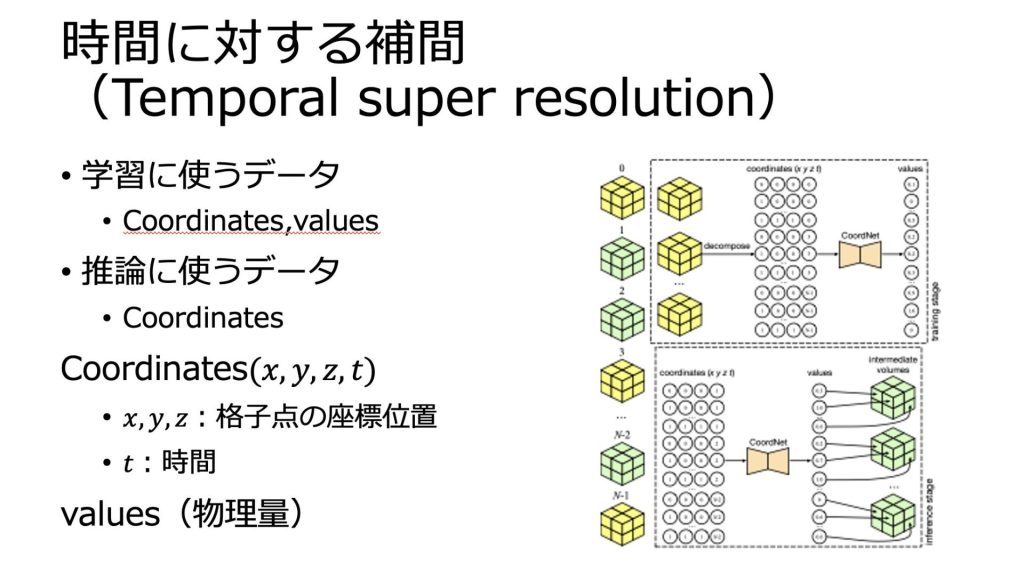
上記のスライドのように、一部のタイムステップからその間の値を補間することで、データ生成を行います。
可視化画像生成
可視化画像生成についてです。
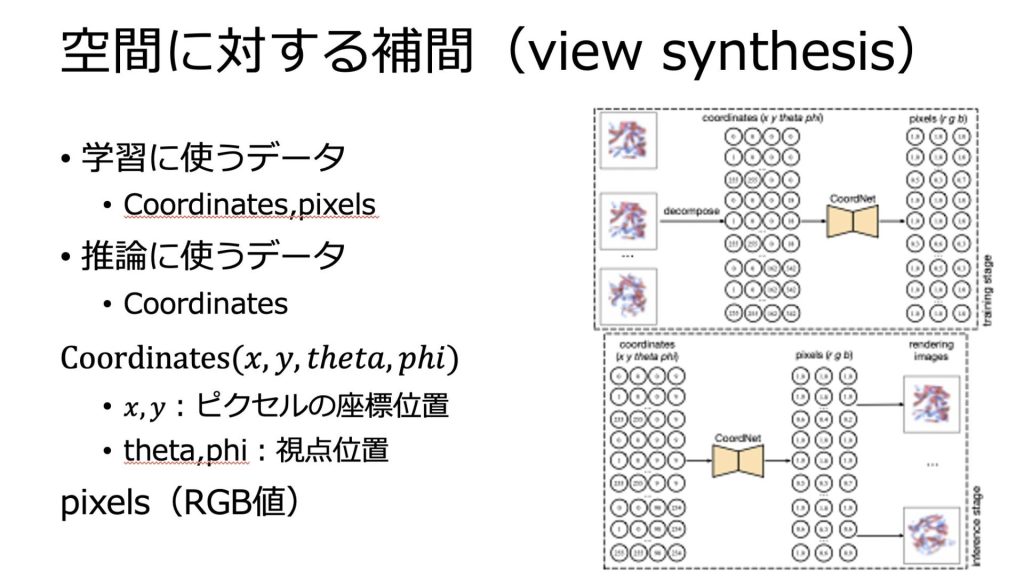
可視化画像生成につきましては、時刻は固定で、視点位置を学習します。
視点位置を学習することで、学習データの視点間を補間できます。
結果
結果は以下です。
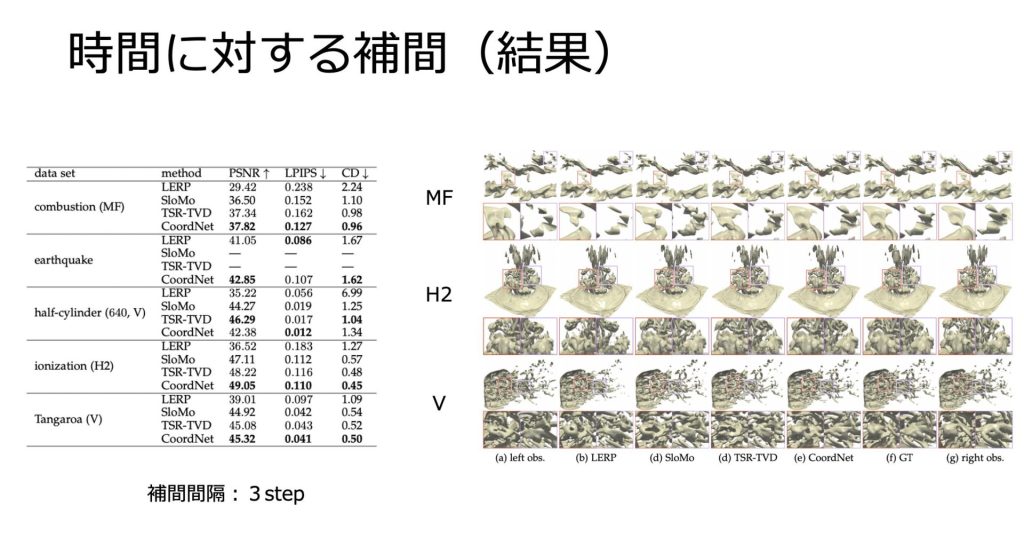
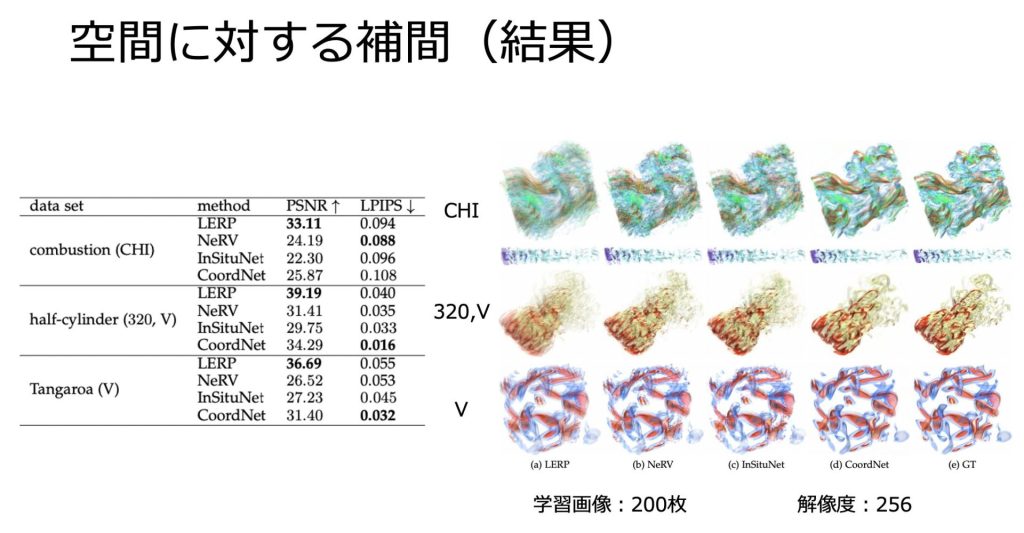
画像類似度誤差が他の手法と比較して、小さい傾向にあることがわかります。
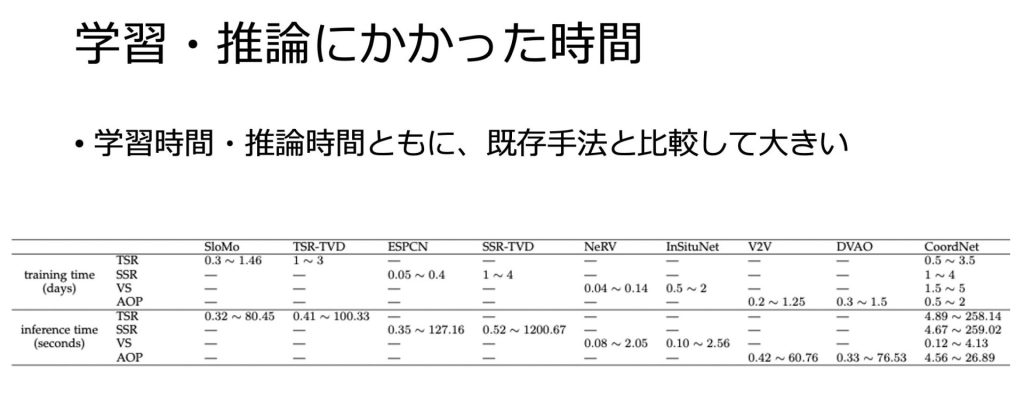
それに対して、学習時間は既存手法と比較して大きくなっています。
考察
考察は以下です。
EnCoder-DeCoderで構成することで、データ生成・画像生成どちらにも対応
ニューラルネットワークベースなので、連続的に値を予測でき、解像度を変更できる
座標を学習に使うため、学習サンプルが増加し、学習時間が大きくなる
今後の課題
論文で述べられている、今後の課題は以下です。
学習時間が比較的大きい
画像解析をするために精度が十分とは言えない
学習にないデータの範囲は推論できない
学習時間が比較的大きいという点で、CoordNetの時間の短縮化を図った論文もあるようなので、次回はそちらの方もまとめていきたいと思います。
最後まで読んでいただきありがとうございました。




コメント