はじめに
こんにちは、可視化研究室でin-situ可視化の研究をしているゆうき(@engieerblog_Yu)です。
今回は私が行なっている研究について紹介していきたいと思います。
背景

近年、スーパーコンピュータの計算性能の向上やシミュレーション技術の発展により、数値シミュレーションが大規模化、複雑化しています。
その結果、シミュレーションの数値データのストレージへの入出力がボトルネックとなっています。
そのボトルネックを低減する手法の一つとして、in-situ 可視化への注目が高まっています。
in-situ可視化では、シミュレーションと同時に可視化を行うことでストレージへの入出力が画像データとなるため、入出力にかかるコストが小さくなり、ボトルネックを低減できます。
しかし、in-situ可視化には、シミュレーションの実行前に可視化に関する設定をしておく必要があるため、対話性が失われてしまうという欠点があります。

ここで、in-situ 可視化に関する研究を2つ紹介します。
1つ目は 4D Street Viewです。
4D Street View では、多数の視点を配置して、様々な条件でin-situ可視化を行います。
そうして出力される大量の画像をデータベース化して、ユーザーの入力に対して、各視点で全方位画像を出力します。
さらにシミュレーション空間を動き回って解析することができます。
2つ目は 最適視点移動経路推定法です。
最適視点移動経路推定法では、重要な現象を捉えた最適な視点経路を推定します。
ユーザーは、重要な現象を最も捉えることができている視点のみを確認し続けることができます。
次にこれらの研究についての問題点について説明していきます。
問題点

先ほど述べたIn-situ可視化関連研究の問題点についてです。
多視点レンダリングを用いた手法では大量の画像をストレージに保存し、それらの画像を表示することによって可視化を行います。
よって大量の画像を保存するためのストレージコストがかかります。
次に、最適視点経路推定法には、対話性を持たせることが困難という問題点があります。
最適視点経路推定法によって出力される動画では現象を最適視点のみでしか確認できません。
もし重要な現象を捉えた視点が複数あり、複数視点から現象を確認したい場合に最適視点経路推定法だけでは確認することができません。
これらの問題点を解決するのが本研究の目的となっています。
目的
本研究の目的についてです。
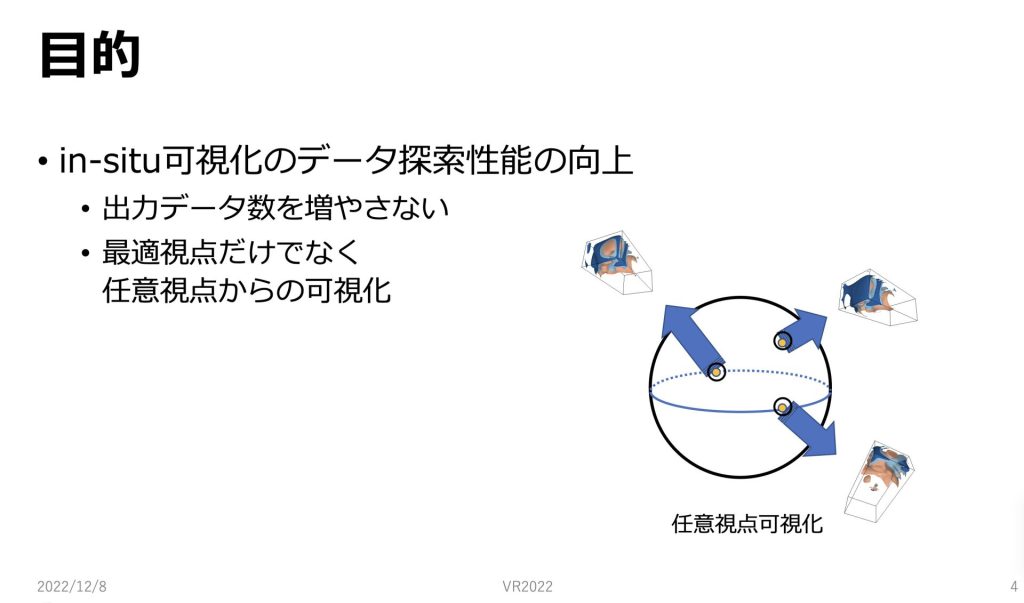
本研究ではin-situ可視化のデータ探索性能の向上を目的としています。
具体的には先ほどのin-situ可視化の問題点である出力画像が大量になってしまうため、ストレージコストがかかってしまうのを防ぐということと最適視点だけでない、任意視点からin-situ可視化を行うということを目的としています。
手法
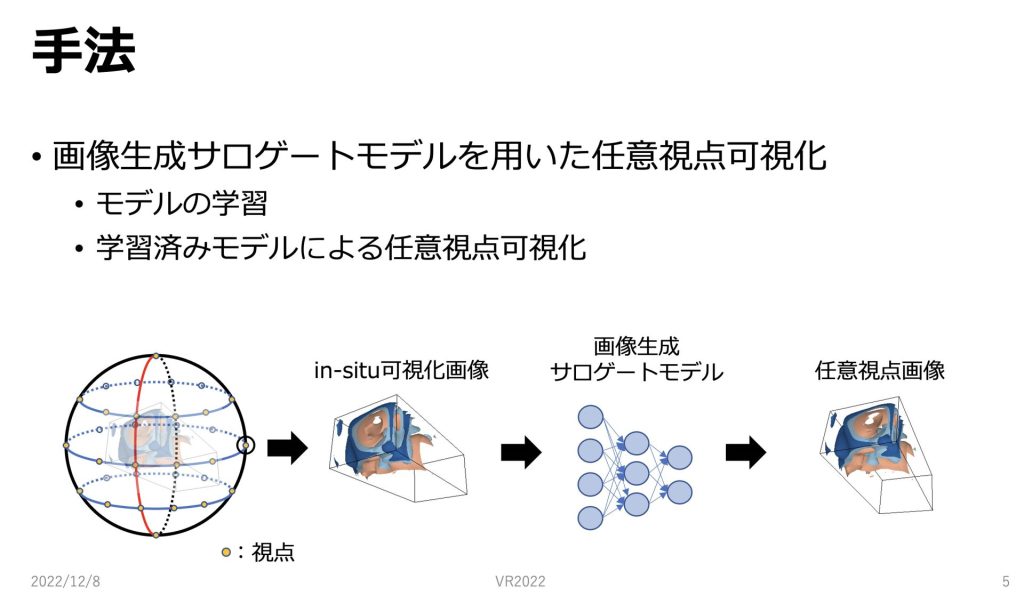
手法といたしましては、画像生成サロゲートモデルを用いて、任意視点可視化を行います。
画像生成サロゲートモデルには、モデルの学習と学習済みモデルによる任意視点可視化という2つの段階があります。
これらについては後ほど順にスライドで具体的に説明します。
図は手法の概要を表していて、in-situ可視化されたレンダリング画像を使って画像生成サロゲートモデルを学習することによって学習済みモデルを作成します。
そのように学習した、学習済みモデルを用いて任意視点可視化を行います。
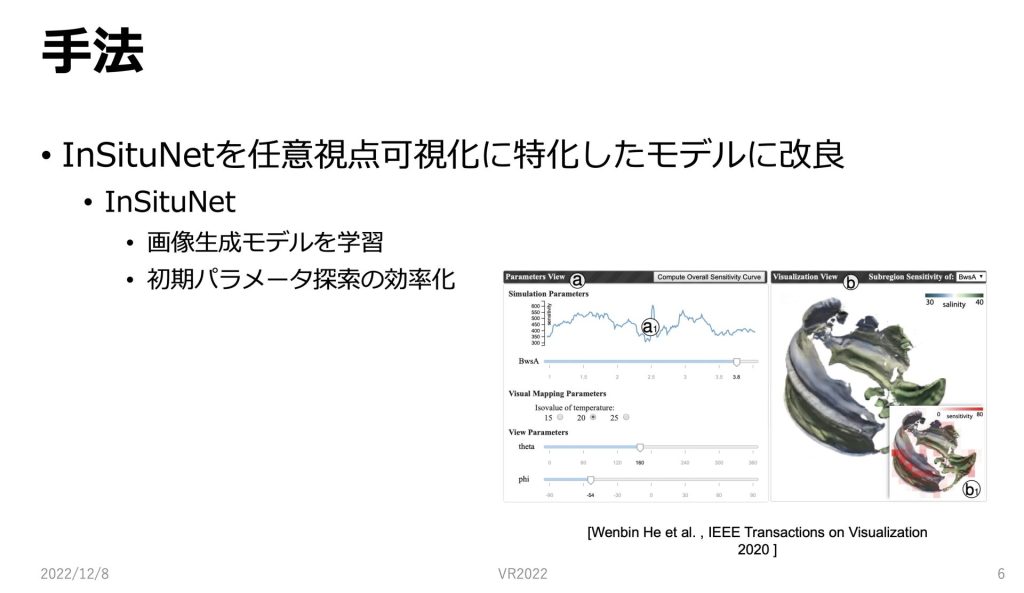
本手法での画像生成サロゲートモデルはinsitunetを任意視点可視化に特化したモデルに改良するということをおこなっています。
insitunet では、in-situ可視化された画像とシミュレーションのパラメータなどをセットに学習して、画像生成モデルを構築します。
そのように学習されたモデルはシミュレーションパラメータなどから画像を高速で生成し、ユーザは対話的にそれらのパラメータ探索を行うことができます。
図はパラメータを動かしながら、その場で可視化している画像です。まずはモデルの学習を行うためのデータ収集について説明していきます。
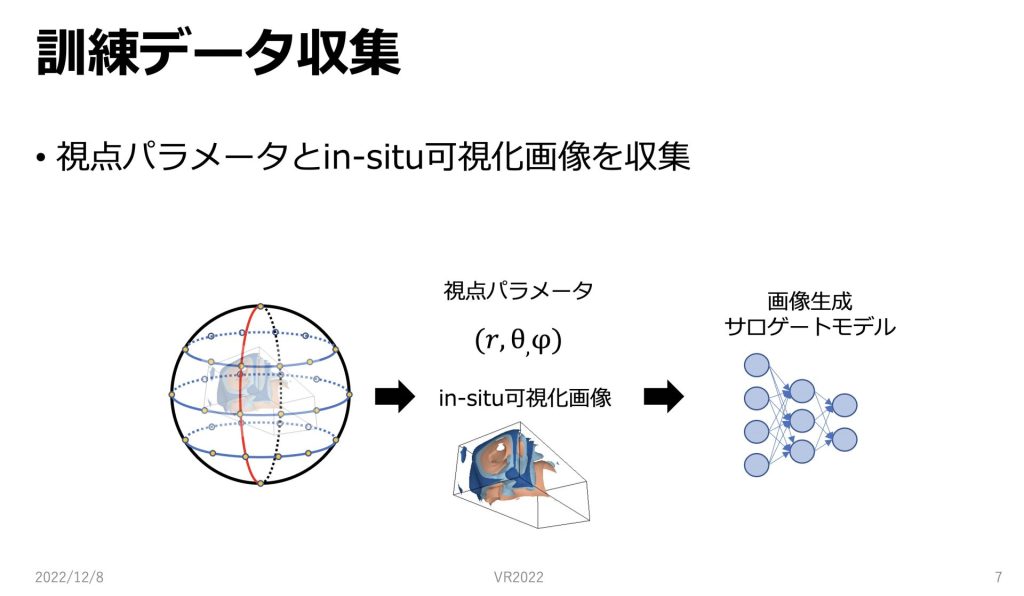
訓練データ収集についてです。
本研究では任意視点可視化を行うために、視点パラメータとin-situ可視化画像を学習に用いています。
球面上に配置される視点、一つ一つに座標情報と、視点からのin-situ可視化画像をセットとして、データを収集します。
そのように収集したデータを画像生成サロゲートモデルの学習に用いていきます。
次に画像ベースサロゲートモデルの学習について説明します。
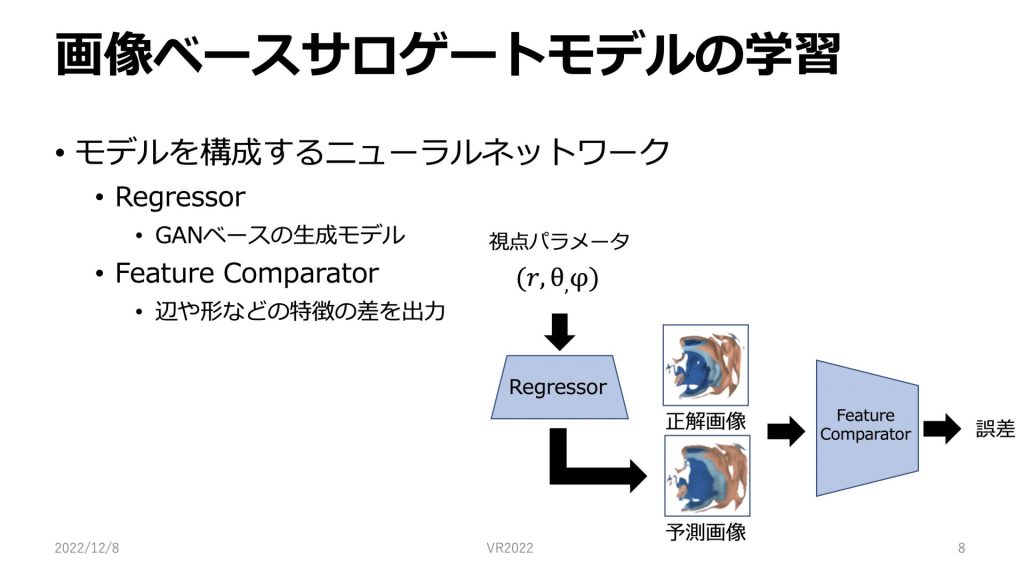
画像ベースサロゲートモデルの学習についてです。
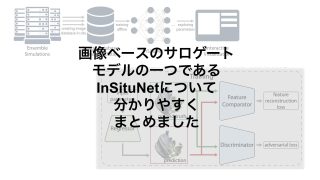
本研究で用いるモデルでは、RegressorとFeature Comparatorという、2つのニューラルネットワークが用いられています。
Regressorは入力パラメータを与えると画像を出力するようなGANベースの生成モデルです。視点のパラメータが含まれています。
Feature Comparatorは正解画像や予測画像を入力として、それらの辺や形などの特徴の差を誤差として出力します。
Feature Comparatorによって出力される誤差が小さくなるようにRegressorを学習していきます。
次にそのように学習された学習済みモデルを使った任意視点可視化について説明したいと思います。
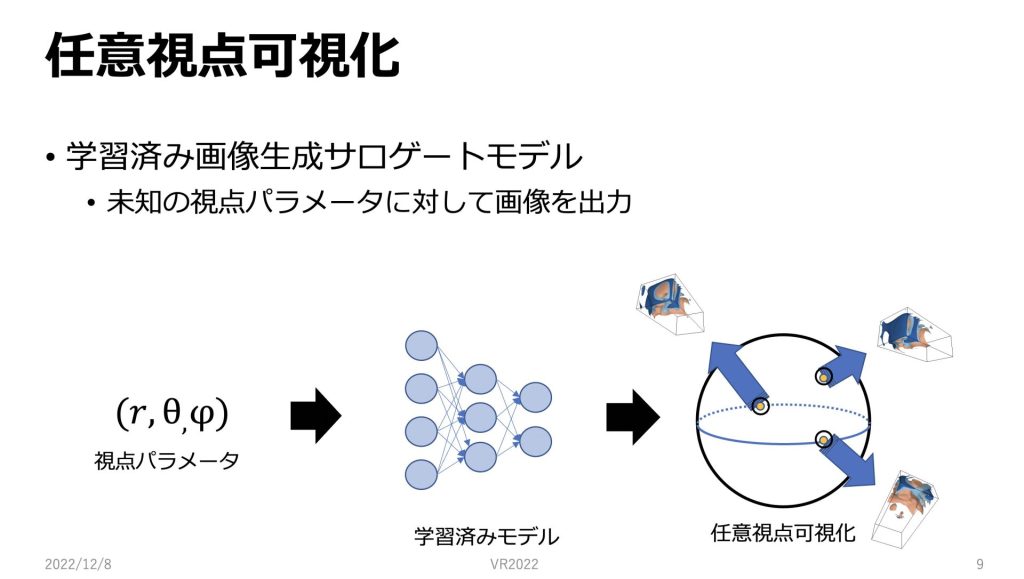
先ほどの手法で、学習されたRegressorを用いて、推論を行ないます。
学習されたモデルに新しい入力パラメータとして、視点パラメータを渡すと、それに対する予測画像を生成します。
従来の多視点レンダリングなどの手法では、既にストレージに保存してある画像しか可視化することができませんが、このように画像生成サロゲートモデルを用いると球面上の任意視点で可視化を行うことができます。
実験

次に手法の検証のために、実験を行いました。
実験に用いたシミュレーションは、歯茎摩擦音発生シミュレーションです。
このシミュレーションは、口の中で発生するジェット流と音の伝播を計算するものです。
OPENFOAMで書かれていて、シミュレーションデータは非構造格子データとなっています。
実行環境はLinux PCで、 シミュレーションは、CPU、画像サロゲートモデルを用いる段階ではGPUを用いています。
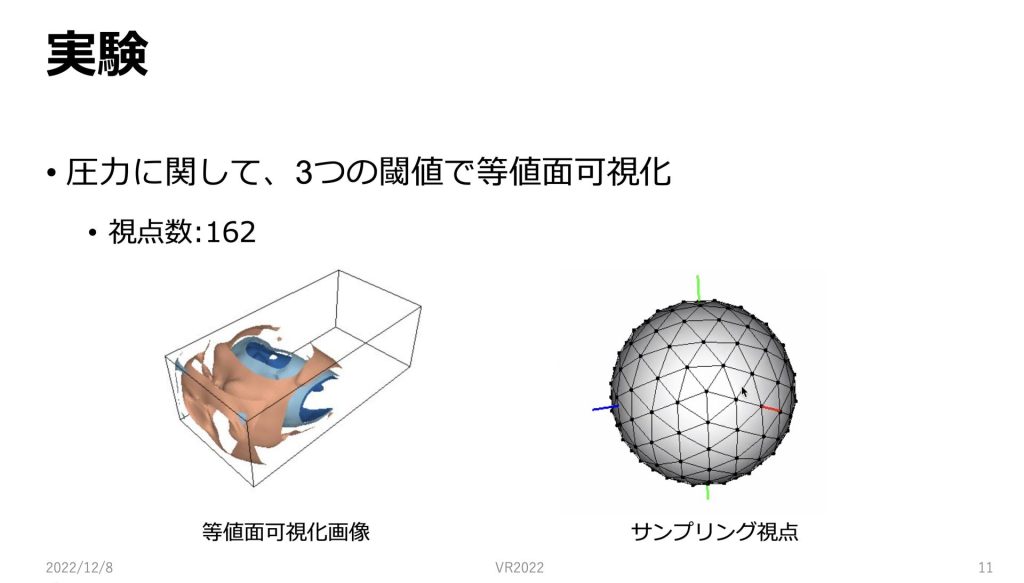
今回の実験では、圧力に関して、3つの閾値で等値面可視化を行ったデータを用いました。
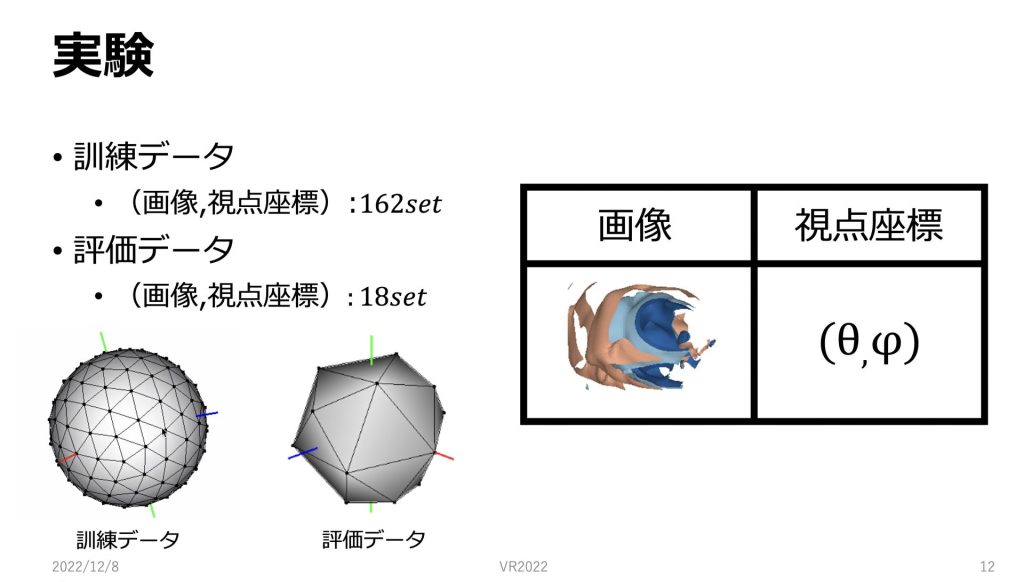
図のように球面上から偏りがないようにサンプリングされた162点からのデータを学習に用いました。
162点のそれぞれに視点座標とin-situ可視化した画像のセットがあるのでそちらのセットをモデルで学習していきます。
視点の座標とその視点からの画像をセットとしてInSituNetの学習を行いました。
今回はモデルの学習に162個のセット、評価データに18個のセットを用いています。
162点のデータは正二十面体を3回分割して、18点のデータは正八面体を1回分割して作成されています。
評価用データも、先ほどと同じように球面上で、図のようにサンプリングを行っています。
評価では、モデルの学習を行った後に、評価データに含まれる新しい視点パラメータをモデルに渡して、生成された画像とその座標での画像を比較するということを行っています。
今回、視点のパラメータはθとφを与えています。
またrは12で固定しています。

In-situ可視化のデータ探索性能が向上できているか確かめるための、評価指標についてです。
まずは、学習モデルによって生成した任意視点画像が妥当であるか確かめるために、視覚的な評価と画像類似度指標を用いて評価を行います。
今回画像類似度指標に関しましては、LPIPS,SSIM,PSNRを採用しました。

先ほど述べた画像類似度指標について具体的に説明します。
LPIPSは学習済みのニューラルネットワークから抽出される特徴量を評価する指標です。値は0〜1の範囲をとり、小さいほど人間の知覚的な類似性が高いとされています。
SSIMは画像の画素値、コントラスト、構造を評価する指標です。
0〜1の範囲をとり、0.9以上であれば一般的に類似性があるとされています。
PSNRは画像にノイズがどれだけ含まれているのかを評価します。
値は0〜無限大の値をとり、30以上であれば一般的に類似性が高いとされています。それでは実験結果について紹介していきたいと思います。
実験結果
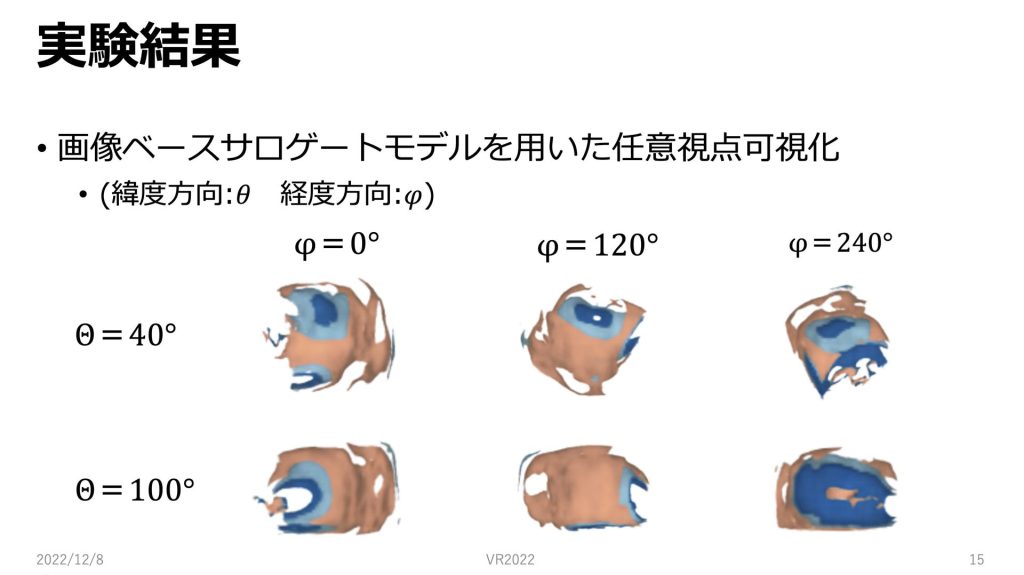
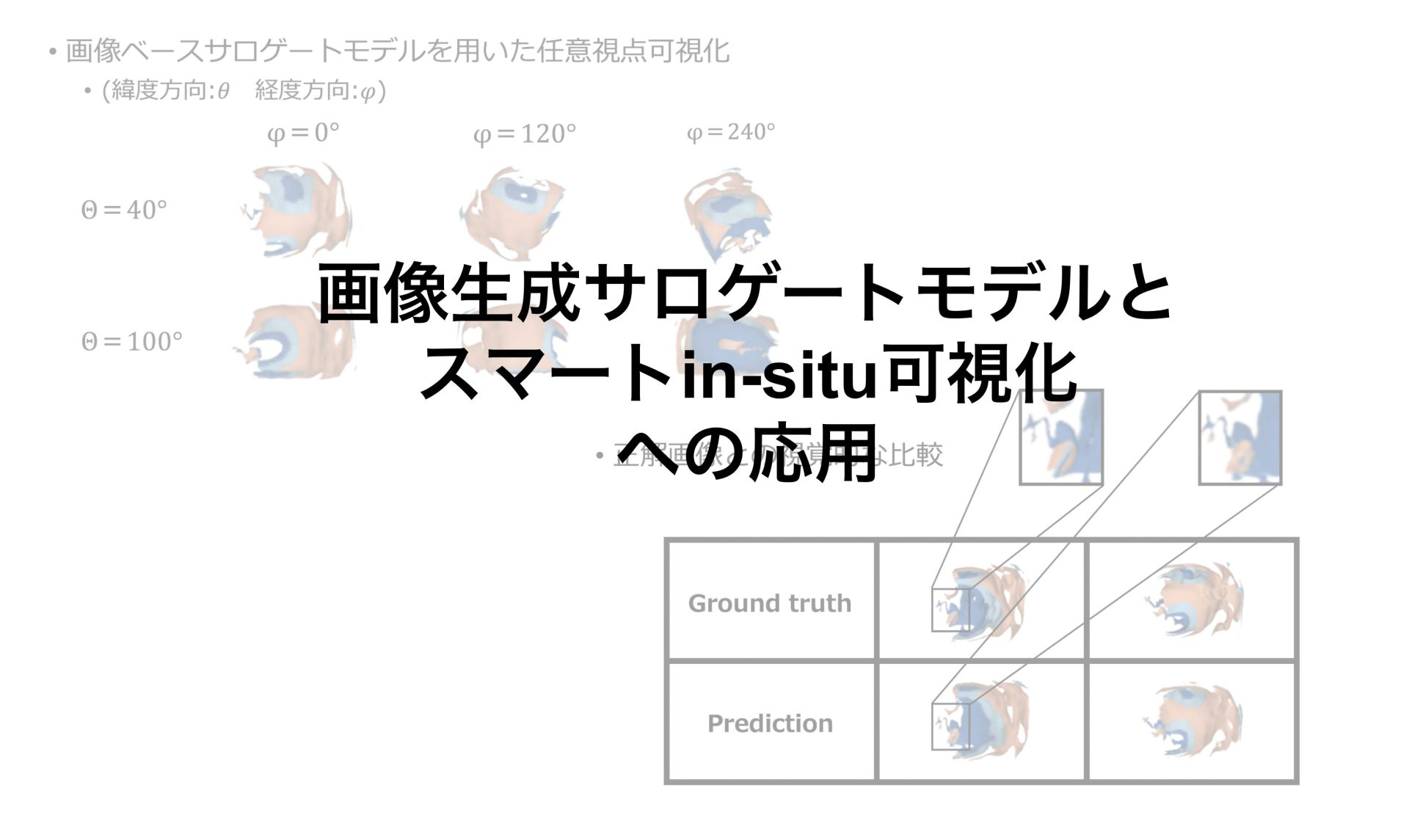
画像ベースサロゲートモデルを用いて任意視点可視化を行いました。画像はサロゲートモデルの出力です。今回Θが緯度方向で、φが経度方向の角度としています。
θ=40の時とθ=100の時で可視化を行いました。
Φを変えると経度方向に視点を回転しているような画像が出力されています。
またθを変えると緯度方向に回転しているような画像が出力されています。
また今回スライドに載せ切ることはできませんでしたが、θとφの値を任意に変更してもスライドに載せた結果と同じような精度で、球面上の任意視点で可視化を行うことができました。
次のスライドで、シミュレーションをin-situ可視化した正解画像と、サロゲートモデルから生成された画像を比較して、どのくらいの誤差があるのかについて示したいと思います。
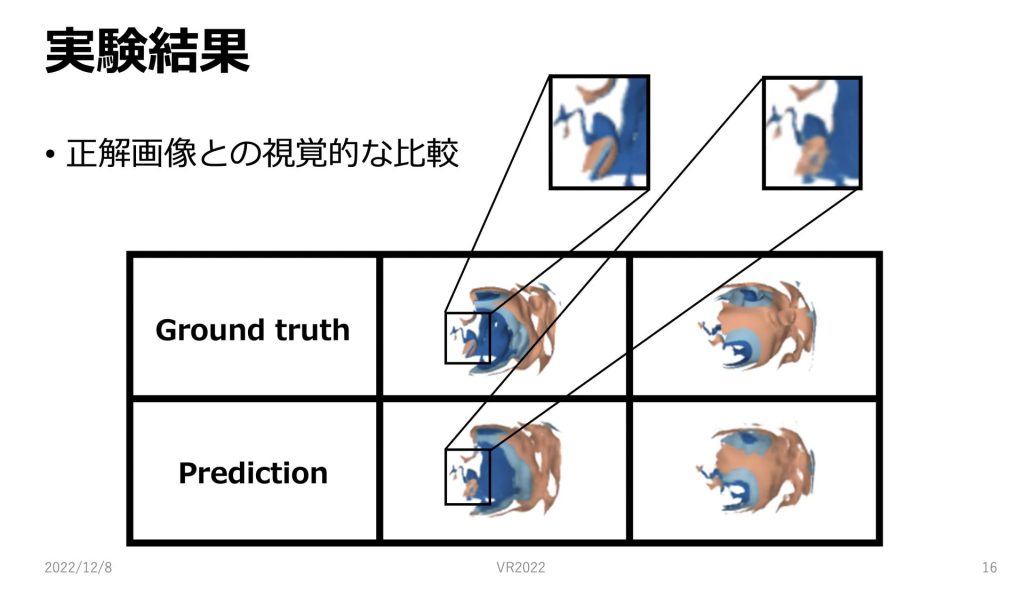
正解画像と画像ベースサロゲートモデルを用いた予測画像の視覚的な比較です。
表の一行目が正解の画像です。
二行目が学習済みモデルから生成された予測画像です。
まず全体的にみると構造はほとんど同じようになっているように思えます。ただし立体感は正解画像に少し劣るように見えます。
次に拡大画像を見てみると細部の形が大まか正確に捉えることができていることがわかります。
次に正解画像と予測画像はどれくらいの誤差があるのか、三つの誤差指標で測った結果を示したいと思います。
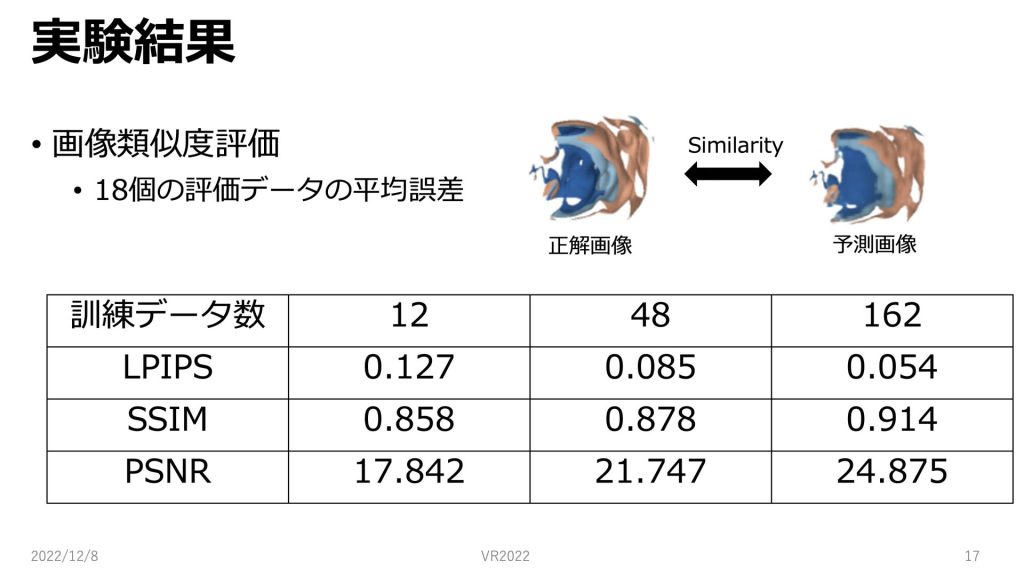
正解画像との誤差を画像類似度で用いられる三つの指標を用いて測定しました。
今回は学習に用いるデータ数を変えて実験を行っています。
一般にLPIPSは低い方が画像類似度が高く、SSIMとPSNRは高い方が画像類似度が高くなります。
値は実験のスライドで述べた18この評価データでの平均値となっています。
学習に用いるデータ数を増やすことで、全ての指標で画像類似度が高くなりました。
今回の実験では162個の場合が最も良い値となりました。
162のSSIMの値を見てみると0.9以上となっているので、これは一般的に画像類似性があると言えます。
それとは対照的にPSNRはどの訓練データ数でも、30以上になっていないので、PSNRだけでは画像類似性があるとは言えないという結果になりました。

次に実行時間と容量についてです。
訓練データ数が162点のモデルの学習に1.140時間、学習済みモデルの実行に0.588秒かかりました。
またストレージにつきましては一視点あたりの画像が約786kbであるのに対して、学習済みモデルは約12MBとなりました。
これは16枚分の画像の容量と学習済みモデルの容量がほとんど同じということになります。
考察

考察です。
目的として、in-situ可視化のデータ探索性能の向上を目的としていましたが、今回用いた手法によってユーザーは、決められた視点だけではなく、任意視点で現象を確認することができます。
また12MB程度の軽量のモデルを一つ保存するのみで、大量の画像を保存しておく必要がないのでストレージコストを削減することができます。
これは任意視点から現象を確認したい時刻がたくさんあった場合、その時刻ごとに大量の画像を保存する必要がなくなることを意味しています。
生成画像の精度につきましては、視覚的な精度と指標を用いた誤差の値を示しましたが、まだ改善の余地があると考えられます。
立体感があまりないことを改善するために、奥行き情報を学習プロセスに組み込むことを考えています。
また学習に用いる視点数をより増やすことで精度がよくなるのかについても検証することを考えています。
まとめと今後の展望

まとめです。
今回私は画像生成サロゲートモデルとスマートin-situ可視化への適応ということで、in-situ可視化のデータ探索性能の向上が確認できました。
今後の展望といたしましては、一つ目はより精度の高い画像を出力できるようなモデルを作ることが挙げられます。
二つ目に可視化パラメータを可変にしたいと考えています。可視化パラメータを可変にすることで、等値面を一つずつ見ることが可能になり、より対話性が大きくなると考えられます。
三つ目にシミュレーションの初期パラメータの探索です。
サロゲートモデルを用いることでシミュレーションの初期パラメータを効率的に探索することができることが予測されます。
最後まで読んでいただきありがとうございました。



コメント