目次
はじめに

どーも、学生エンジニアのゆうき(@engineerblog_Yu)です。
Pythonでスクレイピングの案件を獲得したいと思っている方はいませんか?
今回はPythonでスクレイピングをしたい方に向けてSeleniumを解説していきたいと思います。
Seleniumを用いれば自動でプラウザを開きサイト上の情報を収集することができます。
何度も使われる操作はコードとして残しておけば次に同じ操作をするときにプログラムを回せば一瞬で操作を行うことができて、便利です。
Pythonの案件をこなしたい方やPythonを扱って作業を短縮化したい方はみておいて損はない内容となっています。
特にスクレイピングは案件が豊富なのでPythonで案件を獲得したい方はおすすめの内容です。

(今回私はJupiterNotebookを用いてSeleniumを扱っています。)
noteで完全版を公開中です。
Pythonについて

Pythonとは人工知能、機械学習、ディープラーニング、データ解析などに特化しており、2020年プログラミング言語人気ランキング1位になっているプログラミング言語です。
Pythonについて詳しく知りたい方はこちらのウェブサイトをどうぞ。
Seleniumのimport
まずはseleniumをimportしてあげましょう。
from selenium import webdriverブラウザの開き方
GoogleChromeを開きたい場合このコードを実行してください。
browser = webdriver.Chrome()するとこのようなブラウザが自動で開かれると思います。
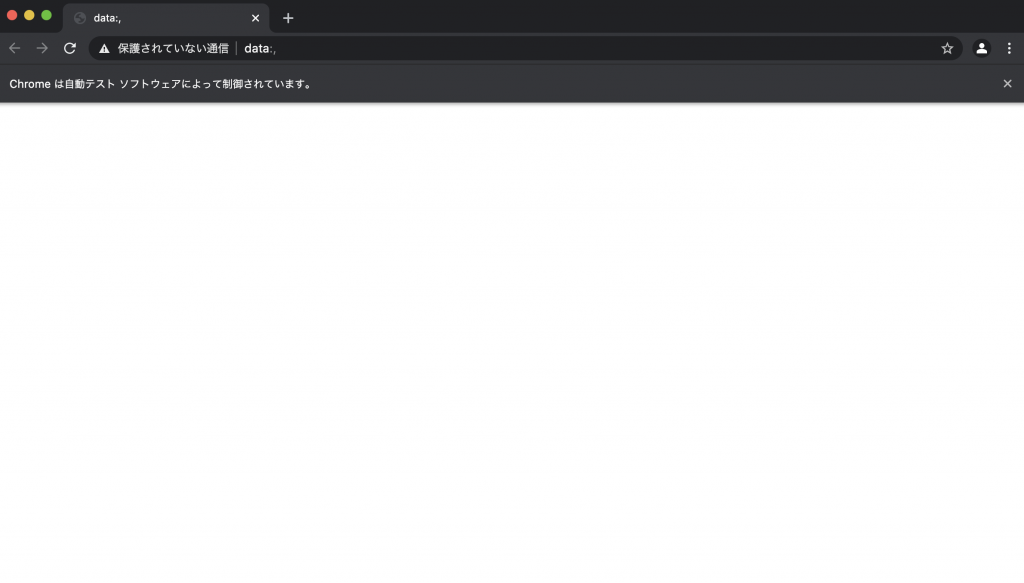
プログラミングにより制御されているブラウザであるので「Chromeは自動テストソフトウェアによって制御されています。」と表示されているはずです。
Webサイトを開く
それでは次に制御されたブラウザをSeleniumを用いて開いてあげましょう。
browser.get('開きたいWebサイトのURL')browser.get()のカッコの中に開きたいWebサイトのURLを入れて実行してあげてください。
※Webサイトによってはスクレイピングが禁止されている場合もあるのでその部分はご自身の方で確認をよろしくお願いします。
Webサイトのidを取得する
elem = browser.find_element_by_id('id名')idとはWebサイト上のHTMLタグのことです。
ここはPythonの知識だけでなくHTMLの知識も必要となってくるので難しいかもしれません。
GoogleChromeを使っている方は右クリックから検証を選べばWebサイトのHTML情報がみれると思います。
そちらのHTML情報から抽出したい情報があるidタグをコードとして打ち込んであげてください。
(なお同じ名前のidタグが複数ある場合は最初のidタグの情報がelemに格納されます。)
複数の同じ名前のidタグの情報を配列として格納したい場合は
elems = browser.find.elements_by_id('id名')としてあげましょう。
elms[0],elems[1],,,とidタグの数だけ配列に格納させることができると思います。
Webサイトのclassを取得する
同様にclassを取得したい場合はこのようにしてあげましょう。
elem = browser.find.element_by_class_name('クラス名')複数の同一の名前のclassを取得したい場合も同じです。
elems = browser.find.elements_by_class_name('クラス名')要素をテキストとして出力する
上記のようにelemに情報を格納してあげたらtextメソッドでテキスト出力してあげることができます。
elem.textまた複数ある場合はfor文を用いてあげましょう。
values = []
for elem in elems:
value = elem.text
values.append(value)こちらのコードを実行してあげれば、valuesというリストに順番にテキストが格納されていきます。
appendメソッドで、valuesというリストに、順番にテキストを入れていくことができます。
Pythonのfor文がわからない方はこちらの記事も一緒にどうぞ。

リストを表にする方法
次にpandasを用いて上記のvaluesをファイル出力してあげましょう。
pandasがわからない方はこちらも合わせてどうぞ。

import pandas as pd
df = pd.DataFrame()
df['値']=valuesdfとしてあげるとpandasのデータフレームの表にしてあげることができます。
CSVファイルやエクセルファイルとして出力
CSVファイルを出力したい場合はこちらのコードを実行してあげてください。
出力したいファイル名の部分に名前をつけてあげてください。
index=FalseとはCSVファイルとして出力する時にindex番号を表示するかしないかという意味です。
index番号を表示させたい方は何も書かなくて大丈夫です。
df.to_csv('出力したいファイル名.csv',index=False)エクセルファイルを出力したい場合はこちらのコードを実行してあげてください。
df.to_excel('出力したいファイル名.xsl',index=False)
【まとめ】スクレイピングの基本的な流れ
スクレイピングの基本的な流れとしては
1、WebサイトのHTML情報を検証から確認する
2、欲しい情報をfind_elements_by~でリストとして格納する
3、Pandasを用いて表にする
4、CSVファイルやエクセルファイルにして出力する
となっています。
他にもBeautifulSoupやRequestsというモジュールを使う場合もあるのでそちらを使う場合におすすめの勉強法を以下で紹介していきたいと思います。
またBeautifulSoupやRequestsについてはこちらの記事で解説しています。


Pythonの勉強方法【おまけ】
Pythonの基礎文法を勉強するにはUdemyというオンラインプログラミング学習プラットフォームがおすすめです。
具体的に言うとこちらの講座です。
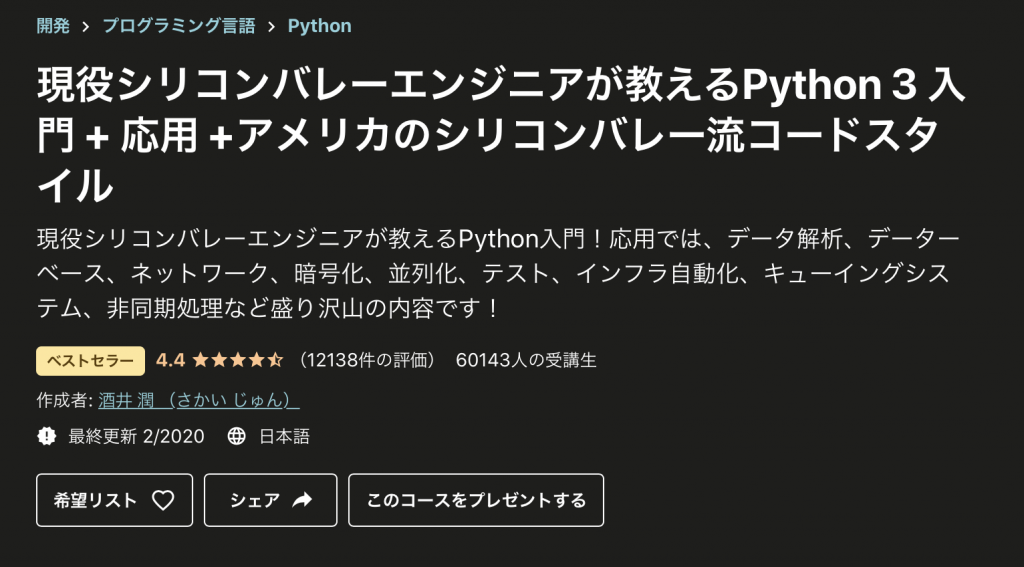
この講座だけで基礎文法だけでなく実践的な応用スキルまで身につけることができます。
めちゃくちゃわかりやすい講座なので気になる方は是非みてみてください。
私が受けたPythonの講座の中では最も良かったですし、この講座だけで案件を獲得できるようになるレベルまでプログラミングを上達させることができると思います。
実際多くの人がWeb上で高評価をしていてUdemyのPython講座といえばこの講座と言われているほどです。
以下のリンクからUdemy講座を参照することができます。
自分の未来に投資しよう。サイバーセール中はUdemyコースが最大90%OFF。またいまにゅさんのこちらの動画もとても説明がわかりやすく実践しながら勉強することができるのでおすすめです。
その他の記事

おわりに

今回はWebスクレイピングに用いられるSeleniumについて紹介しました。
今回紹介したもの以外にもスクレイピングにはBeautifulSoupというものもあるのですがそちらの方も勉強すればスクレイピングの案件をとることができると思います。
Pythonの基礎を学び終えた方や案件を獲得したい方は勉強しておきたい内容です。
興味がある方は上記のUdemyのコースを受けてみるのも良いかと思います。


コメント